
Near-infrared Image Colorization Method Based on a Dilated Global Attention Mechanism
-
摘要: 针对目前卷积神经网络未能充分提取图像的浅层特征信息导致近红外图像彩色化算法存在结果图像局部区域误着色及网络训练不稳定导致结果出现模糊问题,提出了一种新的生成对抗网络方法用于彩色化任务。首先,在生成器残差块中引入自行设计的空洞全局注意力模块,对近红外图像的每个位置理解更加充分,改善局部区域误着色问题;其次,在判别网络中,将批量归一化层替换成梯度归一化层,提升网络判别性能,改善彩色化图像生成过程带来的模糊问题;最后,将本文算法在RGB_NIR数据集上进行定性和定量对比。实验表明,本文算法与其他经典算法相比能充分提取近红外图像的浅层信息特征,在指标方面,结构相似性提高了0.044,峰值信噪比提高了0.835,感知相似度降低了0.021。Abstract: A new generative adversarial network method is proposed for colorization of near-infrared (NIR) images, because current convolutional neural networks fail to fully extract the shallow feature information of images. This failure leads to miscoloring of the local area of the resultant image and blurring due to unstable network training. First, a self-designed dilated global attention module was introduced into the generator residual block to identify each position of the NIR image accurately and improve the local region miscoloring problem. Second, in the discriminative network, the batch normalization layer was replaced with a gradient normalization layer to enhance the network discriminative performance and improve the blurring problem caused by the colorized image generation process. Finally, the algorithms used in this study are compared qualitatively and quantitatively using the RGB_NIR dataset. Experiments show that the proposed algorithm can fully extract the shallow information features of NIR images and improve the structural similarity by 0.044, PSNR by 0.835, and LPILS by 0.021 compared to other colorization algorithms.
-
0. 引言
偏振成像[1]是一种新型的光学成像手段,能够获取多个偏振方向图像,通过偏振信息解析,能够实现同场景多个不同偏振方向图像来表征目标的偏振信息,从而实现对目标的检测。偏振信息解析是偏振成像中的重要环节,目前有很多学者针对不同的应用场景提出了多种偏振信息解析的方法[2-5],其中,沈洁[6]等人根据螳螂虾的复眼能充分利用偏振信息实现水下复杂环境的猎物捕获,提出了基于拮抗机制的偏振仿生信息解析方法,将0°、45°、90°、135°四个偏振方向图像分成2组拮抗图像,通过使2组图像的拮抗信息熵最大来获得偏振方向图像的加权系数,得到偏振拮抗图像,从而实现水下目标探测。但这种方法本质是偏振方向图像间的线性操作,存在计算效率低、解析结果不确定、目标不够突出等问题。
深度学习具有强大的表征能力,可以从高维、复杂以及非线性数据中提取有用的特征,目前在很多领域都有着广泛的应用,如自然语言处理[7]、语音识别[8]、图像处理[9]等。Li[10]等人提出一种基于卷积神经网络(Convolutional Neural Networks,CNN)和残差神经网络(Residual Networks,ResNets)的深度学习架构,用于红外和可见光图像的融合,较好地突显了目标信息,并解决了传统的基于CNN中随着网络深度增加特征信息退化的问题。
偏振图像拮抗过程属于偏振方向图像融合的范畴,本文充分利用深度学习在图像处理上的优势,提出了一种偏振方向图像的双支路拮抗融合网络,主要包括特征提取、特征融合和特征转化3个模块,输入4个不同方向的偏振图像,分成两个支路,低频支路通过合成图像来减少能量的损失,高频支路通过差分图像来突显图像的细节信息。将两个支路处理的结果分别通过深度融合网络进行处理,获取效果更好的融合图像,提高后续目标检测与识别效果。
1. 基本原理
1.1 分焦平面型偏振成像
偏振成像需要获取多个偏振方向图像,常用的获取方式可以分为:分时型、分振幅型、分孔径型和分焦平面型。相对于其他的成像方式,分焦平面型偏振成像具有体积小、重量轻、成本低、能同时获取多个偏振方向图像等优点,成为目前偏振成像获取方法的主流。其基本原理是:在探测器的芯片上集成微型偏振分析器(如图 1所示),在探测器的每4个像元上,耦合0°、45°、90°、135°等4个线偏振方向的偏振分析器,利用4个像元实现1个像素的偏振信息采集。按照微型偏振分析器排列顺序,对探测器输出图像进行重新整合,即可得到0°、45°、90°、135°四个偏振方向图像,如图 2(a)~(d)所示。
![]() 图 2 0°、45°、90°和135°的偏振方向图和合成强度图Figure 2. Polarization and intensity pictures of 0°, 45°, 90°and 135°
图 2 0°、45°、90°和135°的偏振方向图和合成强度图Figure 2. Polarization and intensity pictures of 0°, 45°, 90°and 135°利用偏振成像理论,可以得到合成强度图像I[6],如图 2(e)所示:
$$ I=I\left(0^{\circ}\right)+I\left(90^{\circ}\right) $$ (1) 1.2 仿生偏振拮抗图像
根据螳螂虾复眼的偏振拮抗机制[6],一对正交偏振图像的输入可以形成一个拮抗,如0°和90°偏振方向图像、45°和135°偏振方向图像,将采集到的4组正交偏振图像形成4个偏振拮抗通道,每个通道由相互正交的一对偏振信号组成,各组拮抗信号通过拮抗运算方式可以得到偏振拮抗图像,如下所示:
$$ S_{\mathrm{d}}=k_1 \times I\left(45^{\circ}\right)-k_2 \times I\left(135^{\circ}\right) $$ (2) $$ S_{\mathrm{dd}}=k_3 \times I\left(135^{\circ}\right)-k_4 \times I\left(45^{\circ}\right) $$ (3) $$ S_{\mathrm{h}}=k_5 \times I\left(0^{\circ}\right)-k_6 \times I\left(90^{\circ}\right) $$ (4) $$ S_{\mathrm{v}}=k_7 \times I\left(90^{\circ}\right)-k_8 \times I\left(0^{\circ}\right) $$ (5) 式中:I(0°)、I(90°)、I(45°)和I(135°)分别表示0°、90°、45°和135°的偏振方向图像,ki(i=1, …, 8)为拮抗系数,起到对图像的增强和抑制作用,k的取值范围由人为设定,km≥1(m=1, 3, 5, 7),0<kn≤1(n=2, 4, 6, 8),文献[6]中k是通过遍历所有范围内可能的值,求取偏振拮抗图像信息熵最大来确定,存在计算效率低、结果不确定的问题,使得求取的偏振拮抗图像目标可能不够突出。
1.3 基于深度学习的图像融合
图像融合就是通过处理不同传感器所拍摄的源图像,提取有用的信息或特征,将其整合来改善图像的品质和清晰度[11]。传统图像融合需要人工提取特征,指定融合规则,而基于深度学习的图像融合,利用深度网络对输入图像进行卷积,提取出目标高层特征,再利用卷积将融合后特征转换为融合图像,如图 3所示。相对于可监督图像融合的方法,无监督的方法通过约束融合图像和原图像之间的相似性,克服了大多数图像融合中无参考度量的普遍问题。
2. DANet网络设计
2.1 网络结构
由偏振成像机理可知,每个偏振方向图像能量损失一半。为了提高融合后的图像的亮度,如图 4所示,我们设计了一个低频支路,将4个偏振方向图像通过Concat操作进行连接输入,用于提取每个偏振方向图像的低频特征;根据Tyo[12]的研究结论,偏振差分成像可以突显目标细节信息,因此本文设计了另一个高频支路,将2组拮抗图像进行差分输入,用于提取差分图像的目标高频特征。Huang[13]等人提出了一种密集块结构,其中使用了从任何层到所有后续层的直接连接。这种体系结构可以保存尽可能多的信息,该模型可以改善网络中的信息流和梯度,使网络易于训练,同时,密集连接具有正则化效果,减少了任务的过拟合。受此启发,本文将密集连接加入到差分图像细节特征提取中,用于降低细节信息的损失。设计的网络结构主要包括特征提取、特征融合和特征转化3个模块。
图 4中,特征融合模块将两个支路提取的特征图进行对应像素融合,得到融合特征,特征转化模块利用1×1卷积将融合的特征整合得到输出图像。低频和高频支路均有3个3×3的卷积层,网络参数如表 1所示。
表 1 网络参数Table 1. Network parametersLayer Input channel Output channel Feature extraction Low frequency Conv1 4 128 Conv2 128 64 Conv3 64 50 High frequency Conv4 2 16 Conv5 18 16 Conv6 34 50 Feature fusion Fusion 50 50 Feature transformation Conv7 50 1 2.2 损失函数
在偏振拮抗图像获取中,利用信息熵最大作为评价标准[6],因此本文将信息熵损失Lentropy加入到损失函数中,用于增大融合图像的信息量;结构相似性度量方法作为图像领域使用最广泛的指标之一,该方法基于图像的亮度、对比度和结构3部分来衡量图像之间的相似性,本文将结构相似性损失Lssim加入到损失函数中,用于保持融合图像结构特征;感知损失通常用于图像重建中,恢复出来的图像视觉效果较好,本文将感知损失Lperceptural加入到损失函数中,用于提高融合图像的人眼视觉效果。因此,本文的损失函数L计算公式如下:
$$ L=L_{\text {entropy }} \times \sigma+L_{\text {ssim}} \times \beta+L_{\text {perceptural }} \times \gamma $$ (6) 式中:σ、β、γ为各损失的权重,本文分别取0.1、10、0.1。
1)信息熵损失Lentropy
信息熵(Information Entropy,IE)越大,图像包含的信息越多,为使融合图像信息熵最大,信息熵损失Lentropy定义为:
$$ {L_{{\text{entropy}}}} = \frac{1}{{{\text{IE}} + \varepsilon }} $$ (7) $$ {\text{IE}} = - \sum\limits_{i = 1}^n {p\left( {{x_i}} \right)\log p\left( {{x_i}} \right)} $$ (8) 式中:ε为极小量;xi为随机变量;p(xi)为输出概率函数;n为灰度等级。
2)结构相似性损失Lssim
结构相似性(structural similarity index,SSIM)用于度量两幅图像的相似度,结构相似性损失Lssim定义为:
$$ L_{\text {ssim }}=1-\operatorname{SSIM}(\text { output, } I \text { ) } $$ (9) 式中:SSIM(⋅)表示结构相似性运算;output为输出图像;I为强度图像。
3)感知损失Lperceptural
$$ {L_{{\text{perceptural}}}} = \left\| {{\varPhi _i}\left( {{\text{output}}} \right), {\varPhi _i}\left( I \right)} \right\|_2^2 $$ (10) 式中:Φi(⋅)为VGG16网络第i层特征图。
3. 实验与分析
3.1 实验环境与数据
实验环境如下:训练与测试图像集采用处理器为11th Gen Intel(R) Core(TM) i7-11800H @ 2.30 GHz,系统运行内存为32 GB,GPU显卡为8 GB显存容量的NVIDIA GeForce RTX3080的图形工作站。训练软件运行环境为Python3.9,编程框架为Torch 1.11.0,搭建Cuda10.0用于实验加速。
本文采用LUCID公司的分焦平面型偏振相机(型号:PHX050S-P),如图 5所示。该相机能够同时获取0°、45°、90°、135°四个偏振方向图像,图像分辨率为2448×2048。我们拍摄采集了多种场景目标的9320组偏振方向图像,构建出本文的数据集。
3.2 评价指标及训练参数
本文采用主观定性和客观定量相结合的方法对融合图像进行综合评价,主观评价主要通过人眼观察图像亮度和细节信息,客观评价采用平均梯度[14]、信息熵[15]、空间频率[16]、均值[17]等4个评价指标,定量评估融合效果。
1)平均梯度(Average Gradient,AG)
平均梯度能有效反映出图像层次信息,其值越大,图像层次越丰富,其计算公式为:
$$ \begin{array}{l} {\text{AG}} = \frac{1}{{\left( {M - 1} \right)\left( {N - 1} \right)}} \times \hfill \\ \quad \quad \sum\limits_{i = 1}^{M - 1} {\sum\limits_{j = 1}^{N - 1} {\sqrt {\frac{{{{\left[ {F\left( {i, j} \right) - F\left( {i + 1, j} \right)} \right]}^2} + {{\left[ {F\left( {i, j} \right) - F\left( {i, j + 1} \right)} \right]}^2}}}{2}} } } \hfill \\ \end{array} $$ (11) 式中:F(i, j)为图像的第i行、第j列的灰度值;M、N分别为图像的总行数和总列数。
2)空间频率(Spatial Frequency,SF)
空间频率是图像质量经典的标准之一,其值越大,代表图像质量越高,越清晰,其计算公式为:
$$ {\text{SF}} = \sqrt {{\text{R}}{{\text{F}}^2} + {\text{C}}{{\text{F}}^2}} $$ (12) $$ {\text{RF}} = \sqrt {\frac{1}{{MN}}\sum\limits_{i = 1}^M {\sum\limits_{j = 2}^N {\left[ {{I_{\text{p}}}\left( {i, j} \right) - {I_{\text{p}}}\left( {i, j - 1} \right)} \right]} } } $$ (13) $$ {\text{CF}} = \sqrt {\frac{1}{{MN}}\sum\limits_{i = 2}^M {\sum\limits_{j = 1}^N {\left[ {{I_{\text{p}}}\left( {i, j} \right) - {I_{\text{p}}}\left( {i - 1, j} \right)} \right]} } } $$ (14) 式中:RF是行频率;CF是列频率;M、N为图片的宽高;Ip(i, j)为图像在(i, j)处的像素值。
3)图像均值(Image Mean,IM)
均值即图像像素的平均值,反应图像的平均亮度,平均亮度越大,能量越高,其计算公式为:
$$ {\text{IM}} = \sum\limits_{k = 0}^{L - 1} {{z_k}p\left( {\frac{{{n_k}}}{{MN}}} \right)} $$ (15) 式中:zk为图像的第k个灰度级;L表示图像的灰度等级数目;nk是zk在图像中出现的次数。
本文数据集共计9320组,其中训练集和测试集按照9:1划分,算法的模型由Adam optimizer训练,训练轮次为20,初始学习率为1e-4,每训练4轮学习率衰减一半,详细参数如表 2所示。
表 2 训练参数Table 2. Training parametersParameters Values Training set 8388 Testing set 932 Training round 20 Epoch 4 Optimizer Adam Activation function ReLU Initial learning rate 1e-4 Learning rate decay rate 0.5*lr/4 round 3.3 实验结果分析
为了验证本文算法的有效性,从测试集中随机选取了4组数据,每组数据包含0°、45°、90°和135°偏振方向图像,第1组为室内沙地伪装板目标,第2组为室内标定装置目标,第3组为室外草地伪装板,第4组为水下珊瑚目标,如图 6所示。
![]() 图 6 输入的0°、45°、90°和135°偏振方向图像Figure 6. 0°, 45°, 90° and 135° polarization direction images of input
图 6 输入的0°、45°、90°和135°偏振方向图像Figure 6. 0°, 45°, 90° and 135° polarization direction images of input将上述数据输入到本文训练好的模型中,得到对应的融合图像,根据公式(1)~(5)分别得到合成强度图像I、偏振拮抗图像Sd、Sdd、Sh、Sv,如图 7所示。
从图 7可以看出,本文的融合图像亮度最高,能量最大,说明网络中的低频支路对图像能量的提升效果明显,有效解决了偏振成像中能量降低的问题。从图像细节来说,融合图像的细节效果有较为明显的提升,如第1组本文融合图像中的沙粒更加有颗粒感,伪装板的边缘更加突出,第2组本文融合图像中标定装置的线缆显现出来,背景板的线条更加清晰,而其他图像不太明显,第3组本文融合图像的3块伪装板全部从背景中区分出来,而其他图像只有部分能够区分开,第4组本文融合图像中,珊瑚整体目更亮,珊瑚边缘也更明晰。由于图像能量提升较为明显,可能会造成目标的对比度有所下降,如第一组本文融合图像的伪装板的对比度相较于Sd图和Sh图有所下降,但不影响目标整体的检测效果。
本文将测试集中932组图像输入到模型中,得到对应的932幅融合图像,并根据公式(1)~(5)分别得到932幅合成强度图像I和相应的偏振拮抗图像Sd、Sdd、Sh、Sv。利用平均梯度(AG)、信息熵(IE)、空间频率(SF)和图像灰度均值(IM)指标对其计算均值并进行评价,如表 3所示。
表 3 输出结果的各项评价指标Table 3. Evaluation indexes of the output resultsI Sd Sdd Sh Sv DANet AG 0.0099 0.0128 0.0119 0.0144 0.0126 0.0185 IE 6.06 6.18 6.08 6.15 6.39 7.04 SF 0.35 0.49 0.40 0.46 0.45 0.64 IM 41 49 47 46 57 93 从表 3中可以看出,在4个评价指标上,本文的方法都是最高的,在平均梯度上最少提高了22.16%,最多提高了46.49%;在信息熵上最少提高了9.23%,最多提高了13.92%;在空间频率上最少提高了23.44%,最多提高了45.31%;在图像灰度均值上最少提高了38.71%,最多提高了55.91%。实验结果表明,本文方法得到的融合图像亮度更高,包含的信息量更丰富,可以显现出更多的细节信息。
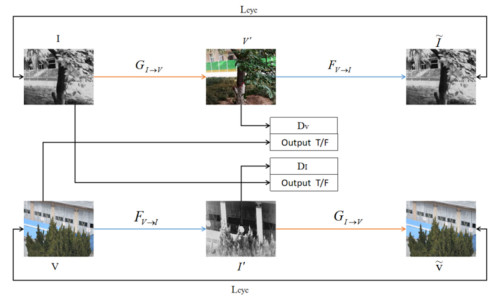
4. 结论
针对偏振方向图像融合效果不明显的问题,本文提出了一种基于双支路拮抗融合网络的偏振信息解析方法,可以解决现有基于拮抗机制的仿生偏振信息解析方法中存在计算效率低、解析结果不确定、目标不够突出等问题,为偏振信息解析提供了一个新的技术途径。本文设计的DANet主要包括特征提取、特征融合和特征转化3个模块。首先,特征提取模块由低频支路和高频支路组成,将0°、45°、90°和135°偏振方向图像连接输入到低频支路,提取能量特征,将2组拮抗图像差分输入到高频支路,提取图像细节特征;其次,将得到的能量特征和细节特征进行特征融合;最后,将融合后的特征转化整合为融合图像。实验表明,通过DANet得到的融合图像在视觉效果和评价指标上均有较为显著提升,在平均梯度、信息熵、空间频率和图像灰度均值上分别至少提升了22.16%、9.23%、23.44%、38.71%。下一步,我们将进一步优化网络结构,以平衡能量支路和细节支路,改善融合图像的对比度;加大水下偏振方向图像在数据集中的比重,优化数据集。
-
![]()
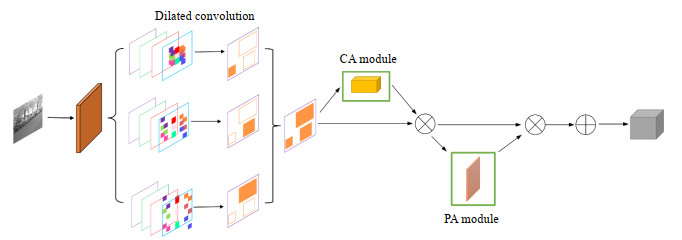
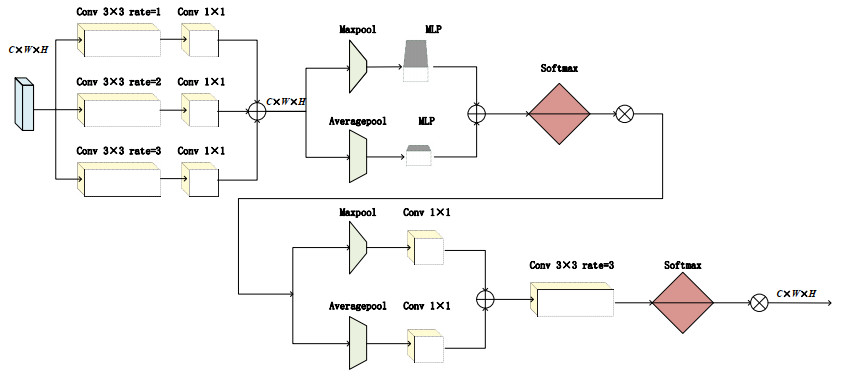
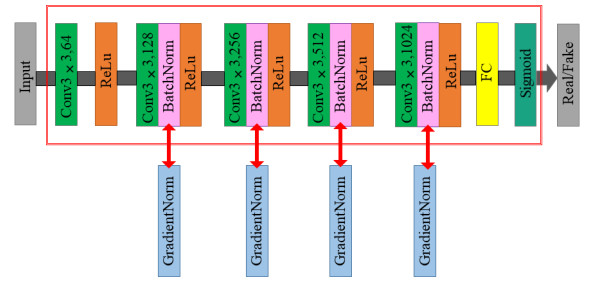
图 4 空洞全局注意力机制模块网络结构
Figure 4. The network architecture of dilated global attention mechanism module
![]()
图 8 各个算法对比结果:(a) 近红外图像;(b) Deoldify[22]结果;(c) Wei[23]结果;(d) In2i[24]结果;(e) CycleGAN算法[7]结果;(f) 本文算法结果;(g) 可见光图像
Figure 8. Comparison results of each algorithm: (a) NIR images; (b) Deoldify[22] results; (c) Wei [23] results; (d) In2i[24] results; (e) CycleGAN[7] Results; (f) Our method results; and (g) Visible images
![]()
图 9 消融实验一对比算法结果:(a) 近红外图像;(b) 实验一结果;(c) 实验二结果;(d) 实验三结果;(e) 实验四结果;(f) 可见光图像
Figure 9. Results of ablation exp.1 comparison algorithm: (a) NIR images; (b) Exp.1 results; (c) Exp.2 results; (d) Exp.3 results; (e) Exp.4 results and (f) Visible images
表 1 指标对比
Table 1 Comparison of indicators
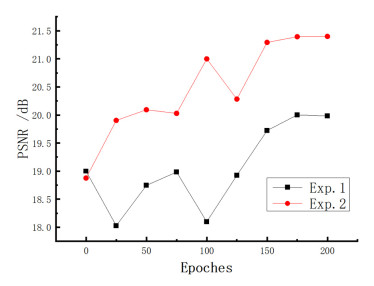
Algorithm Ranch image Mountain image Statue image SSIM PSNR/dB LPIPS SSIM PSNR/dB LPIPS SSIM PSNR/dB LPIPS Deoldify[22]] 0.718 17.088 0.447 0.781 16.682 0.451 0.844 17.397 0.450 Wei[23] 0.743 17.533 0.419 0.699 16.054 0.354 0.705 17.316 0.377 In2i[24] 0.823 16.987 0.371 0.703 18.271 0.435 0.759 17.746 0.362 CycleGAN[7] 0.715 19.787 0.341 0.867 20.738 0.326 0.831 17.681 0.222 Our method 0.832 21.531 0.324 0.904 20.271 0.310 0.835 18.974 0.219  下载: 导出CSV
下载: 导出CSV
表 2 消融实验一指标比对
Table 2 Comparison of ablation experiment 1 metrics
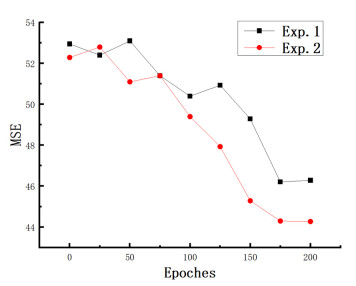
Street Football Building IS FID IS FID IS FID Exp.1 8.263 14.824 7.263 10.942 9.823 14.234 Exp.2 9.072 13.495 8.752 10.234 9.102 11.293 Exp.3 8.273 11.293 9.528 11.293 10.583 14.245 Exp.4 9.210 10.056 9.473 9.351 11.973 10.248
下载: 导出CSV
-
[1] 戴康. 基于超像素提取和级联匹配的灰度图像自动彩色化[J]. 计算机与数字工程, 2019, 47(12): 3169-3172. https://www.cnki.com.cn/Article/CJFDTOTAL-JSSG201912044.htm DAI K. Automatic colorization of grayscale images based on superpixel extraction and cascade matching[J]. Computer and Digital Engineering, 2019, 47(12): 3169-3172. https://www.cnki.com.cn/Article/CJFDTOTAL-JSSG201912044.htm
[2] 曹丽琴, 商永星, 刘婷婷, 等. 局部自适应的灰度图像彩色化[J]. 中国图象图形学报, 2019, 24(8): 1249-1257. https://www.cnki.com.cn/Article/CJFDTOTAL-ZGTB201908004.htm CAO L Q, SHANG Y X, LIU T T, et al. Locally adaptive grayscale image colorization[J]. Journal of Image and Graphics, 2019, 24(8): 1249-1257. https://www.cnki.com.cn/Article/CJFDTOTAL-ZGTB201908004.htm
[3] Tomihisa Welsh, Michael Ashikhmin, Klaus Mueller. Transferring color to greyscale images[C]//ACM TOG, 2002, 21(3): 277-280.
[4] Reinhard E, Adhikhmin M, Gooch B, et al. Color transfer between images[J]. IEEE Computer Graphics and Applications, 2001, 21(5): 34-41.
[5] 冯佳男, 江倩, 金鑫, 等. 基于深度神经网络的遥感图像彩色化方法[J]. 计算机辅助设计与图形学学报, 2021, 33(11): 1658-1667. https://www.cnki.com.cn/Article/CJFDTOTAL-JSJF202111003.htm FENG J N, JIANG Q, JINX, et al. Colorization method of remote sensing image based on deep neural network[J]. Journal of Computer-Aided Design and Computer Graphics, 2021, 33(11): 1658-1667. https://www.cnki.com.cn/Article/CJFDTOTAL-JSJF202111003.htm
[6] CHENG Z, YANG Q, SHENG B. Deep colorization[C]//Proceedings of the IEEE International Conference on Computer Vision, 2015: 415-423.
[7] Isola P, ZHU J Y, ZHOU T, et al. Image-to-image translation with conditional adversarial networks[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 1125-1134.
[8] Deblina Bhattacharjee, Seungryong Kim, Guillaume Vizier, et al. DUNIT: detection based unsupervised image-to-image translation[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020: 4787-4796.
[9] 万园园, 王雨青, 张晓宁, 等. 结合全局语义优化的对抗性灰度图像彩色化[J]. 液晶与显示, 2021, 36(9): 1305-1313. https://www.cnki.com.cn/Article/CJFDTOTAL-YJYS202109011.htm WAN Y Y, WANG Y Q, ZHANG X N, et al. Adversarial grayscale image colorization combined with global semantic optimization[J]. Chinese Journal of Liquid Crystals and Displays, 2021, 36(9): 1305-1313. https://www.cnki.com.cn/Article/CJFDTOTAL-YJYS202109011.htm
[10] 左岑, 杨秀杰, 张捷, 等. 基于轻量级金字塔密集残差网络的红外图像超分辨增强[J]. 红外技术, 2021, 43(3): 251-257. http://hwjs.nvir.cn/article/id/a1540103-27df-466a-a058-1fd126ff5aec ZUO Q, YANG X J, ZHANG J, et al. Super-resolution enhancement of infrared images based on lightweight pyramidal dense residual networks[J]. Infrared Technology, 2021, 43(3): 251-257. http://hwjs.nvir.cn/article/id/a1540103-27df-466a-a058-1fd126ff5aec
[11] 姜玉宁, 李劲华, 赵俊莉. 基于生成式对抗网络的图像超分辨率重建算法[J]. 计算机工程, 2021, 47(3): 249-255. https://www.cnki.com.cn/Article/CJFDTOTAL-JSJC202103032.htm JIANG Y N, LI J H, ZHAO J L. Image super resolution reconstruction algorithm based on generative adversarial networks[J]. Computer Engineering, 2021, 47(3): 249-255. https://www.cnki.com.cn/Article/CJFDTOTAL-JSJC202103032.htm
[12] 张振江, 张宝金, 刘伟新, 等. 基于深度卷积网络的矿岩图像分割算法研究[J]. 采矿技术, 2021, 21(5): 149-152, 171. https://www.cnki.com.cn/Article/CJFDTOTAL-SJCK202105041.htm ZHANG Z J, ZHANG B J, LIU W X, et al. Research on mining rock image segmentation algorithm based on deep convolutional network[J]. Mining Technology, 2021, 21(5): 149-152, 171. https://www.cnki.com.cn/Article/CJFDTOTAL-SJCK202105041.htm
[13] 姚永康. 基于对抗式迁移学习的皮肤病变图像分割方法研究[D]. 西安: 西京学院, 2021. YAO Y K. Research on Skin Lesion Image Segmentation Method Based on Adversarial Transfer Learning[D]. Xi'an: Xijing University, 2021.
[14] 吴杰, 段锦, 董锁芹, 等. DFM-GAN网络在跨年龄模拟的人脸识别技术研究[J]. 计算机工程与应用, 2021, 57(10): 117-124. https://www.cnki.com.cn/Article/CJFDTOTAL-JSGG202110015.htm WU J, DUAN J, TONG S Q, et al. DFM-GAN networks in cross-age simulation for face recognition[J]. Computer Engineering and Applications, 2021, 57(10): 117-124. https://www.cnki.com.cn/Article/CJFDTOTAL-JSGG202110015.htm
[15] 刘高天, 段锦, 范祺, 等. 基于改进RFBNet算法的遥感图像目标检测[J]. 吉林大学学报: 理学版, 2021, 59(5): 1188-1198. https://www.cnki.com.cn/Article/CJFDTOTAL-JLDX202105026.htm LIU G T, DUAN J, FAN Q, et al. Remote sensing image target detection based on improved RFBNet algorithm[J]. Journal of Jilin University(Science Edition), 2021, 59(5): 1188-1198. https://www.cnki.com.cn/Article/CJFDTOTAL-JLDX202105026.htm
[16] LI C, WAN D M. Precomputed real-time texture synthesis with markovian generative adversarial networks[C]//2016 European Conference on Computer Vision of IEEE, 2016: 702-716.
[17] LI Y, CHEN Y, WANG N, et al. Scale aware trident networks for object detection[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV), 2019: 6053-6062.
[18] Woo S, Park J, Lee J Y, et al. CBAM: convolutional block attention module[C]//2018 European Conference on Computer Vision, 2018: 3-19.
[19] Ioffe S, Szegedy C. Batch normalization: accelerating deep network training by reducing internal covariate shift[C]//2015 Proceedings of the 32nd International Conference on International Conference on Machine Learning, 2015: 448-456.
[20] Bhaskara V S, Aumentado-Armstrong T, Jepson A D, et al. GraN-GAN: piecewise gradient normalization for generative adversarial networks[C]//Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2022: 3821-3830.
[21] Brown M, Süsstrunk S. Multi-spectral sift for scene category recognition[C]//2011 IEEE Conference on Computer Vision and Pattern Recognition, 2011: 177-184.
[22] Jason Antic. jantic/deoldify: a deep learning based project for colorizing and restoring old images (and video!)[J/OL] [2019-10-16]https://github.com/jantic/DeOldify.
[23] LIANG W, DING D, WEI G. An improved dual GAN for near infrared image colorization[J]. Infrared Physics & Technology, 2021, 116(4): 103764-103777.
[24] Perera P, Abavisani M, Patel V M. In2i: Unsupervised multi-image-to-image translation using generative adversarial networks[C]//2018 International Conference on Pattern Recognition, 2018: 140-146.
-
期刊类型引用(0)
其他类型引用(1)









计量
- 文章访问数: 130
- HTML全文浏览量: 33
- PDF下载量: 44
- 被引次数: 1
