
Fast-Steering-Mirror Slip-Mode Control Based on Extended State Observer
-
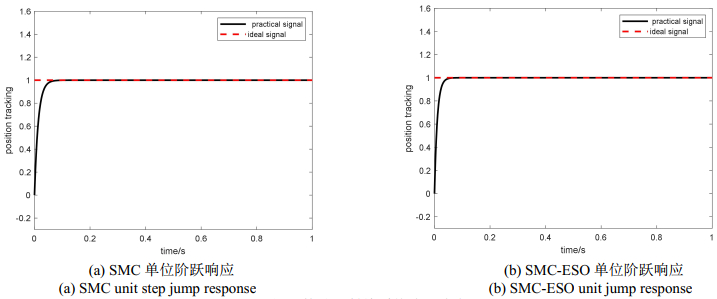
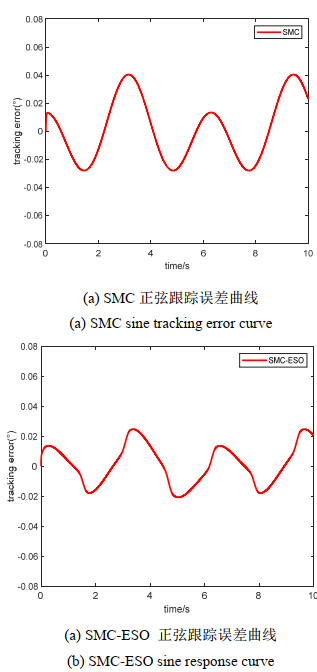
摘要: 快速反射镜需要具备快速的动态响应以及抗干扰能力。针对快速反射镜系统在工作环境中,因自身运动以及外界干扰等因素所引起的不确定性干扰问题,本文在对快速反射镜系统进行分析与数学建模的基础上,提出一种基于扩张状态观测器的改进滑模控制器,利用扩张状态观测器观测出未知扰动并直接补偿给控制器,在保证跟踪误差在期望精度范围的同时,有效减少了抖振,便于工程实现。通过仿真实验证明:相较于传统滑模控制器,采用基于扩张状态观测器的改进滑模控制器,上升时间缩短了50.4%,调节时间上缩短了39.1%,跟踪精度提高了30.5%,满足了快速反射镜的工作要求,提高了动态性能。Abstract: Fast-steering mirrors require a rapid dynamic response and an anti-interference ability. In this study, an improved sliding-mode controller based on an extended state observer is proposed to solve the uncertain interference caused by self-movement, external interference, and other factors in the working environment of a fast-steering-mirror system based on the analysis and mathematical modeling of the fast-steering-mirror system. The proposed system uses an extended state observer to observe the unknown disturbance and directly compensate it to the controller, which effectively reduces chattering and facilitates engineering implementation. The simulation results show that compared with the traditional sliding-mode controller, the improved sliding-mode controller based on the extended state observer decreases the rise and adjustment times by 50.4% and 39.1%, respectively, and increases the tracking accuracy by 30.5%. These values satisfy the working requirements of the fast mirror and improves the dynamic performance.
-
0. 引言
随着人工智能和汽车传感器技术[1]的快速发展,智能车辆目标检测在良好的道路环境中达到了较高的水平[2]。基于视觉的检测算法被提了出来[3],然而,在夜间、雾天等低见度环境中仍然存在很大的挑战。
目前采用的低能见度增强的方法主要有直方图均衡化、基于Retinex的方法以及深度学习的方法,这些单模态增强方法通常只具备某一方面的信息,对目标检测性能提升有限,无法满足精度的要求,因此双模态图像融合技术应运而生。目前的双模态图像融合方法主要有基于多尺度变换[4]的融合方法,该方法存在图像细节信息丢失严重和图像信噪比低的等问题;基于稀疏表示[5]的融合方法,该方法容易造成图像纹理细节信息的丢失以及效率较低的问题;基于神经网络[6]的融合方法是目前主要的研究方向,但也存在模型参数不易设置、算法复杂耗时以及泛化能力亟待提升的问题。在目标检测方面,深度学习强大的特征提取能力能够轻松处理各种交通场景中的目标检测任务。目标检测的准确性和鲁棒性也优于传统方法和机器学习算法。算法主要分为两类:基于区域生成的两阶段法如Faster R-CNN(Regions with CNN features)[7]、SPP-Net(Spatial Pyramid Pooling Networks)[8]和作为回归问题看待的单阶段法如SSD(Single Shot Detector)[9]、YOLOv4(You Only Look Once v4)[10]、M2Det [11]。两阶段法的检测准确度略高于单阶段法,然而计算繁琐,难以满足实时性要求。近年来,基于单阶段法的车辆检测模型不断优化和改进,检测精度逐渐超过了两阶段法。最重要的是,单阶段法的检测速度远远优于两阶段法[12]。
由于可见光具有较详细的纹理信息和较高的空间分辨率,而红外光具有较强的穿透力,不受光照影响[13]。针对夜间单一可见光模态图像亮度低、对比度低、动态范围小、噪声大、色彩失真等图像质量低而导致漏检、误检、检测精度低的情况发生的问题。本文将可见光与红外光两种模态的图像通过一种新的融合算法进行图像融合,使得融合后的图像在表达详细的纹理即梯度和边缘等信息的同时突出显示辐射即亮度和对比度等信息,对实际环境有更全面、清晰的描述,从而更有利于人眼的识别和高级任务的分类或识别,然后将融合后的图像输入到YOLOv5网络进行训练,产生针对可见光与红外光双模态图像的低见度道路运动目标的检测模型,最后对于实际的低见度道路运动目标进行检测以验证目标检测的精度与实时性。
1. 低能见度目标检测技术路线
为提高对夜间等低见度交通环境下道路运动目标的检测精度,运用车载相机捕获可见光图像(提供目标纹理、颜色等信息)、红外相机捕获红外光图像(提供目标空间位置、轮廓等信息),将两种配准后的双模态图像按时间序列输入到双模态图像融合算法进行图像的预处理,从而得到具有纹理细节以及辐射信息的高质量图像,提升单阶段目标检测技术在低见度场景下的目标检测的鲁棒性,最后输入到YOLOv5网络模型以进行低见度道路目标的实时检测,如图 1所示。
![]() 图 1 低能见度下道路运动目标检测技术路线Figure 1. Technical route of road moving target detection in low visibility
图 1 低能见度下道路运动目标检测技术路线Figure 1. Technical route of road moving target detection in low visibility2. 双模态图像融合
2.1 引入红外图像
如图 2所示,在白天且光照明亮的环境下,左边可见光的彩色图要比右边红外图分辨率高的多,能清楚地分辨出目标的表面纹理特征,避免了背景颜色相似对运动目标识别造成的干扰。如图 3所示,在夜晚无光或光照不足的环境下,左边的可见光彩色图很难分辨出道路运动目标,而右边的红外图则能明显地分辨出运动目标的轮廓信息。因此,在不同的光线照射环境下,可见光彩色图与红外图这两种模态有各自的表征优势。为适应白天与黑夜等低见度的交通环境,将可见光彩色图与红外图共同作为网络的输入,丰富检测目标的特征。
![]() 图 2 白天光照明亮时彩色图与红外图对比Figure 2. Comparison between color image and infrared image when the light is bright in the daytime
图 2 白天光照明亮时彩色图与红外图对比Figure 2. Comparison between color image and infrared image when the light is bright in the daytime![]() 图 3 夜晚光照不足时彩色图与红外图对比Figure 3. Comparison between color image and infrared image in case of insufficient light at night
图 3 夜晚光照不足时彩色图与红外图对比Figure 3. Comparison between color image and infrared image in case of insufficient light at night2.2 双模态图像融合算法
本文选用的双模态图像融合算法有双尺度Tif(Two-scale Image Fusion)图像融合算法[14]、基于小波变换的图像融合算法[15]以及一种的新图像融合算法。其中双尺度图像融合与基于小波变换的图像融合算法是属于传统图像融算法中基于变换域的方法,首先将源图像变换到某个变换域,然后在该变换域内以系数的形式进行图像融合,最后再用逆变换得到融合图像。新的图像融合算法属于深度学习图像融合技术。采用双分支结构并利用设计好的基于梯度残差密集快GRDB(Gradient Residual Dense Block),强化提取丰富的细节特征,如图 4所示。分别将不同模态的图像源进行特征提取,通过concat操作将两种模态的特征进行融合,再对融合的特征进行多轮的卷积与激活操作得到融合的图像,将融合的图像输入到语义分割网络架构中得到语义分割结果。其中语义分割的结果与labels之间的损失为语义损失,这样语义损失能够将分割所需的语义信息反传回融合网络从而促使融合网络能够有效地保留源图像中的语义信息。而图像融合的结果与图像源的损失为内容损失,这两种损失共同约束网络的优化。网络结构如图 5所示。
内容损失定义如下:
$$ L_{\text {content }}=L_{\text {int }}+\alpha L_{\text {texture }} $$ (1) 式中:Lcontent为内容损失;Lint为强度损失;Ltexture为纹理损失。Lcontent由Lint和Ltexture线性加权组成,而强度损失用于优化双模态图像融合的表观强度、纹理损失则强制融合图像包含更多的细粒度信息,α为平衡强度损失与纹理损失的权重系数。
$$ L_{\text {int }}=\frac{1}{H W}\left\|I_{\mathrm{f}}-\max \left(I_{\mathrm{ir}}, I_{\mathrm{vi}}\right)\right\|_1$$ (2) $$L_{\text {texture }}=\frac{1}{H W}\left\||\nabla I_{\mathrm{f}} \mid-\max \left(\left|\nabla I_{\mathrm{ir}}\right|,\left|\nabla I_{\mathrm{vi}}\right|\right)\right\|_1$$ (3) 式中:H为输入图像的高度;W为输入图像的宽度;Iir为红外图像,Ivi为可见光图像,If为融合图像,∇为Sobel算子。
运用最大选择策略来融合红外光与可见光的强度分布,而最优纹理则是红外光与可见光纹理的最大聚合。
语义损失定义如下:
$$ L_{\text {semantic }}=L_{\text {main }}+\lambda L_{\text {aux }} $$ (4) 式中:Lsemantic为语义损失;Lmain为主损失;Laux为辅损失;λ为平衡主损失与辅损失的权重系数。Lsemantic由Lmain与Laux线性加权组成。
$$ L_{\text {main }}=-\frac{1}{H W} \sum\limits_{h=1}^H \sum\limits_{w=1}^W \sum\limits_{c=1}^c L_{\mathrm{so}}^{(h, w, c)} \log \left(I_{\mathrm{s}}^{(h, w, c)}\right) $$ (5) $$ L_{\mathrm{aux}}=-\frac{1}{H W} \sum\limits_{h=1}^H \sum\limits_{w=1}^W \sum\limits_{c=1}^C L_{\mathrm{so}}^{(h, w, c)} \log \left(I_{\mathrm{sa}}^{(h, w, c)}\right) $$ (6) 融合网络总的损失为:
$$ L=L_{\text {content }}+\beta L_{\text {semantic }} $$ (7) 式中:C为图像的通道数;Is为分割网络结果;Isa为辅助分割结果;Lso为分割标签转换的one-hot向量;β为表征语义损失的超参数。
2.3 融合效果对比
本文采用Tif、基于小波变换以及本文的图像融合技术,对输入的低见度的可见光图与红外光图进行双模态图像融合,如图 6所示为融合前后对比图,可以看出融合后的图像包含可见光模态的纹理信息以及红外光的模态的轮廓信息,使运动目标很容易显现在低见度环境中。以第一列图像为例,原始的低见度可见光彩色图与经过3种算法融合后的图像信息,如表 1所示。
表 1 双模态图像融合后图像信息对比Table 1. Comparison of image information after bimodal image fusionE SD EN AG SF Tif 46.416 25.285 5.473 1.987 6.853 Wavelet 45.818 23.694 5.401 2.090 6.115 This Article 64.176 28.444 5.326 2.355 7.185 由表 1可知,本文的算法在图像均值(E)上明显高于前两种算法,因此视觉上更加明亮,利于低见度目标的识别。在标准差(SD)上也明显高于前两种算法,因此图像的灰度级分布较前两种算法处理的结果越分散,图像所携带的信息量就越多。而在信息熵(EN)指标3种算法基本持平。平均梯度(AG)反映纹理变换的特征、空间频率(SF)反映图像灰度的变化,两项指标均为评价图像清晰度的指标,值越大则图像越清晰,本文的算法在两项指标的值也较高于前两种算法,因此图像更加清晰。综合各项量化指标来看,本文的双模态融合算法优于前两种融合算法。具体的融合效果如图 6所示。
由图 6对比得知融合后的图像整体都较原图增亮了,且经过本文算法融合的图像均值最大,图像最明亮。前两种算法融合结果的背景区域的纹理细节受到热辐射信息的干扰,无法保留目标的锐化边缘,此外,显著目标的强度信息不同程度地被削弱。本文的融合结果与背景区域的可见光图像Original_V相似,显著目标的像素强度与红外图像Original_I一致,本文的方法成功地保留了可见图像的纹理细节并保持了显着目标的强度。
3. 深度网络模型训练
3.1 算法原理
YOLO[16]核心思想是将目标检测问题转化为一个回归问题,对于输入的被检图像,经过YOLO网络即可输出预测bounding box的4个坐标参数bx、by、bh、bw、所属的类别以及置信度to,且置信度由bounding box准确度Pr与网格包含目标的概率IoU共同决定。YOLOv5损失函数由定位损失、分类损失以及置信度损失构成,其中定位损失采用GIOU Loss函数、分类损失采用BECLogits函数、置信度损失采用交叉熵损失函数。图 7为anchor box与bounding box转换示意图,其中绿色实线框是要预测的bounding box,蓝色虚线框是Anchor box,其中bx、by、bh、bw、to计算公式为:
![]() 图 7 Anchor box与bounding box转换示意图Figure 7. Schematic diagram of conversion between anchor box and bounding box
图 7 Anchor box与bounding box转换示意图Figure 7. Schematic diagram of conversion between anchor box and bounding box$$\begin{aligned} &b_x=\sigma\left(t_x\right)+C_x \\ &b_y=\sigma\left(t_y\right)+C_y \\ &b_w=P_w \mathrm{e}^{t_w} \\ &b_h=P_h \mathrm{e}^{t_h} \\ &t_{\mathrm{o}}=P_{\mathrm{r}} * \mathrm{IoU} \end{aligned} $$ (8) 式中:Cx为预测边界框中心所在网格左上角网格的横坐标;Cy代表预测边界框中心所在网格左上角网格的纵坐标;Pw为该单元格对应anchor box的宽;Ph为该单元格对应anchor box的高;tx为预测bounding box中心距所处网格左上角的相对宽偏移量;ty为预测bounding box中心距所处网格左上角的相对高偏移量;σ为sigmoid函数。
将SPPNet应用到特征提取的末端,使得网络的输入图像大小不再受约束。在网络的Neck部分应用了PANet(Path Aggregation Network),将底层较多的位置信息自底向上地传给上层特征,以提高检测的定位精度。将CSPNet(Cross Stage Partial Network)的思想运用用到网络的Neck部分,加强特征融合的能力。通过输入参数可以改变锚框的大小以适应道路运动目标大小。如图 8所示为整体网络结构图。
3.2 夜间道路目标检测网络的训练
本文基于Pytorch框架的YOLOv5网络进行训练和验证的。训练集与验证集的比例为3:1,其中训练集有187张图片,验证集有63张图片。根据图像处理的方式分为原彩色图、Tif融合图、基于小波变换融合图以及本文算法融合图 4组。通过可视化工具观察训练过程中损失函数的变化,一共进行300轮训练后,损失函数不再降低并趋于稳定,根据每组模型在验证集上的不同指标进行比较。
4. 试验结果及分析
4.1 数据集
选用RGB-Thermal城市场景图像双模态数据集进行训练验证。该数据集包含1569张图像(白天拍摄820张,夜间拍摄749张)。在该数据集中包含驾驶过程中常见的八类障碍物(汽车、人、自行车、弯道、汽车停止、护栏、色锥和凹凸)。数据集根据图像采集时的时间序列分为三部分。每个时间序列是取自视频连续帧图片,相邻图片相差不大。因此本实验对该数据集清洗,去除冗余图像后选出夜间等低见度图像一共250张图片,并对数据集中的汽车与货车等车辆使用Make Sense打上标签Car,将行人标记为Pedestrian,将骑自行车的人标记为Cyclist,最终重新整理的数据集包含Pedestrian、Car、Cyclist,并按照3:1的比例划分为训练集train和val,其中训练集187张图片,验证集63张图片。
4.2 实验参数设置
试验环境配置:CPU i7-10750H、GPU Nvidia 1660Ti、CUDA11.4、Windows10、Python3.8。
参数设置:初始学习率设为0.01,最终学习率,以one_cycle形式从0.01衰减至0.01*0.2;warmup_ epochs:设为5,使用预热有助于使模型收敛速度变快,效果更好;epochs设为300,batch-size设为16。
4.3 评价指标
对于多目标检测任务用准确率p、召回率r、相似系数F1分数以及平均精度mAP以及在不同IoU阈值(从0.5到0.95,步长0.05)上的平均mAP,mAP_0.5:0.95作为评价模型的指标。其中:
$$ p=\frac{\text { 真正例数量 }}{\text { 预测为正样本数量 }}=\frac{\mathrm{TP}}{\mathrm{TP}+\mathrm{FP}} $$ (9) $$ r=\frac{\text { 真正例数量 }}{\text { 实际为正样本数量 }}=\frac{\mathrm{TP}}{\mathrm{TP}+\mathrm{FN}} $$ (10) $$ F_1=\frac{2 p r}{p+r}$$ (11) $$ \mathrm{mAP}=\frac{1}{K} \sum\limits_{i=1}^K \int_0^1 p_i \mathrm{~d} r $$ (12) 式中:TP为真正例数即正确检测框数;FP为假正例数即错误检检测框数;FN为假反例数即漏检框数;K为目标检测类别数;本文K取3。
4.4 结果分析
通过300轮训练后,每组试验均生成了最好的模型。取IoU=50作为模型衡量的参数,四组模型所达到的不同指标如表 2所示。不同指标对比图如图 9所示。实际检测效果对比如图 10所示。
表 2 IoU=50时各项指标对比Table 2. Comparison of various indicators when IoU=50p r F1 mAP Visible Light 0.62 0.56 0.57 0.55 Tif 0.75 0.71 0.64 0.68 Wavelet 0.76 0.78 0.75 0.79 This Article 0.81 0.78 0.78 0.81 由表 2可知,本文算法处理后的模型在IoU=50时,准确率p较未经双模态图像融合处理的模型提高30.65%,召回率提高39.29%,其他指标也有明显提高。相比于Tif融合算法处理的模型在各项指标也有明显的提升,相比于小波变换融合算法处理的模型在各项指标也有一定程度的提升。在融合效率方面,Tif融合算法达到21 fps、小波融合算法为18 fps,由于本文算法采用GPU加速,融合速度超过80 fps,其融合速度满足实时检测要求。
由图 9可知,经过双模态图像技术融合后的图像训练的3种检测模型的各项指标明显高于未经处理的单模态图像训练的检测模型的各项指标。其中本文模型将准确率p由71.51%提升到88.86%,高于Tif的83.68%以及小波变换的85.53%、召回率r由55.99%提升到76.17%,高于Tif的66.18%以及小波变换的72.40%,其他各项指标均明显提高且高于其他两种算法。考虑到本文的融合效率明显高于其他两种融合算法,因此选用本文融合算法作为双模态图像融合处理技术。
由图 10可知,若采用单模态的低见度可见光图像作为被检对象,a列存在将漆黑的部分误检为人,b、c列均存在漏检情况,而d列则完全检测不到目标。而将双模态融合的图像作为被检对象时则明显改善了检测效果,但Tif双模态融合检测效果较另外两种差,基于小波变换融合与本文的检测效果基本满足夜间运动目标的检测精度要求。
5. 结论
本文基于双模态融合的低能见度道路目标实时检测算法对夜间主要道路目标进行检测。
1)通过引入红外图像来解决夜间运动目标难以辨别的问题,并通过基于传统方法的双模态图像融合算法Tif、小波变换算法与基于深度学习的双模态图像融合算法等对可见光模态与红外光模态进行融合,从而丰富图像的特征,实现对低对比度、高噪点、强眩光下等低能见度道路目标的感知增强,进一步改善夜间道路目标检测网络的训练效果。
2)将采用不同双模态融合算法处理的训练结果和与未经图像处理的单模态可见光模态的训练结果进行对比,本文算法在夜间环境识别道路目标的能力显著提高、识别精度由75.51%提升到88.86%,提升了17.68%、融合与检测的速度超过了60 fps,为低能见度下的道路目标检测提供了较好的参考结果。
-
![]()
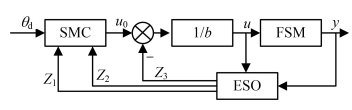
图 2 基于扩张状态观测器的滑模控制结构框图
Figure 2. Fragments of sliding mold control structure based on the extended state observer
-
[1] Pereira P, Hunwardsen M T, Cahoy K. Characterization of laser thermal loading on microelectromechanical systems-based fast steering mirror in vacuum[J]. Optical Engineering, 2020, 59(5): 056109.
[2] 刘力双, 夏润秋, 吕勇, 等. 音圈电机快速控制反射镜研究现状[J]. 激光杂志, 2020, 41(9): 1-7. LIU L S, XIA R Q, LV Y, et al. The status research statue of quickly control permiars of audio motors[J]. Laser Journal, 2020, 41(9): 1-7.
[3] 冯爽. 快速反射镜的高精度控制策略研究[D]. 西安: 西安电子科技大学, 2021. FENG S. Research on High-precision Control Strategies for Fast Mirrors[D]. Xi'an: Xi'an University of Electronic Science and Technology, 2021
[4] 刘泊, 郭建英, 孙永全. 压电陶瓷微位移驱动器建模与控制[J]. 光学精密工程, 2013, 21(6): 1503-1509. LIU B, GUO J Y, SUN Y Q. Cangers ceramic micro -displacement driving model modeling and control[J]. Optical Precision Engineering, 2013, 21(6): 1503-1509.
[5] WANG G, RAO C. Adaptive control of piezoelectric fast steering mirror for high precision tracking application[J]. Smart Materials & Structures, 2015, 24(3): 035019. DOI: 10.1088/0964-1726/24/3/035019
[6] 李贤涛, 张晓沛, 毛大鹏, 等. 高精度音圈快速反射镜的自适应鲁棒控制[J]. 光学精密工程, 2017, 25(9): 2428-2436. LI X T, ZHANG X P, MAO D P. et al. Adaptive robust control of high-precision sound rims of fast reflectors[J]. Optical Precision Engineering, 2017, 25(9): 2428-2436.
[7] 丁科, 黄永梅, 马佳光. 抑制光束抖动的快速反射镜复合控制[J]. 光学精密工程, 2011, 19(9): 1991-1998. DING K, HUANG Y M, MA J G. Fast-reflective mirror composite control of the beam jitter[J]. Optical Precision Engineering, 2011, 19(9): 1991-1998.
[8] 赵继庭, 金刚石, 高旭辉. 基于快速反射镜的模糊自适应PID控制算法研究[J]. 激光与红外, 2018, 48(6): 756-761. ZHAO J T, JIN G S, GAO X H. Research on the blog PID control algorithm based on fast purchables[J]. Laser and Infrared, 2018, 48(6): 756-761.
[9] 韩京清. 自抗扰控制技术——估计补偿不确定因素的控制技术[M]. 北京: 国防工业出版社, 2008. HAN J Q. Self-antidation Control Technology-Control Technology of Estimation Compensation Uncertain Factors[M]. Beijing: National Defense Industry Press, 2008.
[10] Youm W, Lee S Q, Park K. Optimal design and control of a voice coil motor driven flexure hinge for AFM actuator[C]//IEEE/asme International Conference on Advanced Intelligent Mechatronics, 2005: 325-328.
[11] 黄浦, 杨秀丽, 修吉宏, 等. 音圈致动快速反射镜的降阶自抗扰控制[J]. 光学精密工程, 2020, 28(6): 1365-1374. HUANG P, YANG X L, XIU J H, et al. The audio coil actuates the reduction of self-relief control of fast reflectives[J]. Optical Precision Engineering, 2020, 28(6): 1365-1374.
[12] GAO Z. Active disturbance rejection control: a paradigm shift in feedback control system design[C]//American Control Conference of IEEE, 2006: 1656579.
-
期刊类型引用(1)
1. 吕行,富容国,常本康,郭欣,王芝. 透射式GaAs光电阴极性能提高以及结构优化. 物理学报. 2024(03): 250-256 .  百度学术
百度学术
其他类型引用(2)

 下载:
下载:










计量
- 文章访问数: 107
- HTML全文浏览量: 44
- PDF下载量: 22
- 被引次数: 3
