
Review of Research on Low-Light Image Enhancement Algorithms
-
摘要:
低照度图像增强是图像处理领域的重要问题之一,近年来,深度学习技术的迅速发展为低照度图像增强提供了新的解决方案,且具有广阔的应用前景。首先,全面分析了低照度图像增强领域的研究现状与挑战,并介绍了传统方法及其优缺点。其次,重点讨论了基于深度学习的低照度图像增强算法,根据学习策略的不同将其分为五类,分别对这些算法的原理、网络结构、解决问题进行了详细的阐述,并按时间顺序将近6年基于深度学习的图像增强代表算法进行了对比分析。接着,归纳了当前主流的数据集与评价指标,并从感知相似度和算法性能两个方面对深度学习算法进行测试评估。最后,对低照度图像增强领域改进方向与今后研究作了总结与展望。
Abstract:Low-light image enhancement is an important problem in the field of image processing. The rapid development of deep learning technology provides a new solution for low-light image enhancement and has broad application prospects. First, the current research status and challenges in the field of low-light image enhancement are comprehensively analyzed, and traditional methods and their advantages and disadvantages are introduced. Second, deep learning-based low-light image enhancement algorithms are classified into five categories according to their different learning strategies, and the principles, network structures, and problem-solving capabilities of these algorithms are explained in detail. Third, representative deep learning-based image enhancement algorithms from the last six years are compared and analyzed in chronological order. Fourth, the current mainstream datasets and evaluation indexes are summarized, and the deep learning algorithms are tested and evaluated in terms of perceived similarity and algorithm performance. Finally, directions for improvement and future research in the field of low-light image enhancement are discussed and suggested.
-
Keywords:
- low-light images /
- image enhancement /
- deep learning /
- image processing /
- low-light dataset
-
0. 引言
目标检测是计算机视觉领域的研究热点之一[1]。无人机搭载红外相机进行目标检测在军事侦察[2]、智能交通、智能农业[3]等领域有着广泛应用。然而,主流目标检测算法依赖于白天或其他光照充足场景,在夜间或缺乏光照的弱光场景往往精度不足。红外航拍场景具有视场广、灵活性高等特点,其图像采集通过热成像仪感知环境温度信息,不易受光照影响,在弱光环境下亦可获得较好的成像效果。因此红外航拍目标检测已经成为计算机视觉领域的重点课题之一。
早期的航拍目标检测一般利用手工设计特征[4]方式,但航拍红外图像往往背景复杂、检测目标小、尺度变化大,对传统方法提出更大的挑战。当前,得益于计算机视觉技术的发展,基于深度学习的检测方法成为主流,依据检测流程可分为单阶段(One-Stage)和双阶段(Two-Stage)两类。双阶段目标检测以Faster-RCNN(Region-based Convolutional Neural Networks)[5]系列为代表,一般精度较高。单阶段目标检测以YOLO(You Only Look Once)[1, 6-8]系列和SSD(Single Shot MultiBox Detector)[9]为代表。机载平台往往内存功耗受限、算力不足,单阶段算法一般复杂度更低,运行速度更快,更适合应用于边缘设备,YOLO是其中的典型代表。
对比可见光图像,红外图像对比度低、纹理信息不丰富,尽管面向可见光大数据的深度模型已取得巨大进步,但面向红外图像实现准确而鲁棒的目标检测仍具有很大的挑战[4]。可见光图像纹理信息丰富,但易受光照条件影响,红外成像不受光照影响,因此对红外与可见光图像进行图像融合是一项有益的探索[10],但同步成像或彩色-红外图像配准成本较高。因此仅使用热红外图像实现目标检测[11]成为领域的研究重点之一。
视觉显著性对深入挖掘图像信息具有重要意义。显著性目标检测(Salient Object Detection, SOD)[12]将图像中显著主体目标进行像素级分割,通过颜色、深度等信息与周围环境的差异定位显著性目标,已成功应用于目标识别[13-14]等领域。研究表明,显著图网络获得的语义特征能更好地表达目标不同尺度的上下文信息[15]。但显著图缺乏纹理特征,本文将红外图像显著图与原始红外图像进行融合,以挖掘更多信息。
基于以上分析,针对红外航拍场景特点和需求,本文提出了一种融合视觉显著性的红外航拍行人检测方法。首先以YOLOv4-tiny作为基础网络,针对红外航拍场景数据特点,通过K-Means算法进行先验框重聚类,增加目标检测针对性。进而采用先进的深度显著性目标检测网络U2-Net[15]从热红外图像生成显著性图,与原始热图像进行融合挖掘更多图像信息。并分析基于像素级加权融合和通道替换融合两种方法对航拍红外目标检测的影响,最后实验验证了本文方法的有效性。为其他红外目标检测任务提供了一种可行的研究思路和丰富的实验参考。
1. 相关工作
1.1 目标检测
在过去20年中,可见光图像是目标检测的主要对象。传统目标检测主要通过手工提取特征的方式,例如方向梯度直方图(Histogram of Oriented Gradient, HOG)[4],但面向复杂场景精度有限。
近年来,基于深度学习的目标检测取得了重大突破,主要分为双阶段目标检测和单阶段目标检测。前者以R-CNN[5]系列为代表,该类算法准确率较高,但计算成本高,一般不适用于无人机机载航拍目标检测。
单阶段算法最具代表性的是YOLO系列算法[9],YOLO基于回归思想,直接在输出层回归边界框(Bounding Box)的位置和所属类别,速度上更占优势[6]。YOLOv2[7]借鉴了Faster RCNN的锚框(anchor)机制,使得速度和精度上升了一个台阶。YOLOv3[8]引入Darknet-53特征提取网络与多尺度检测,使用逻辑回归代替了Softmax,检测效果达到了当时业界的领先水平。Alexey[1]等对YOLOv3的网络结构、数据预处理等进行优化提出YOLOv4,实现了检测速度和精度的再一次突破。其中YOLOv4-tiny是面向边缘计算优化的检测模型。
1.2 红外目标检测
红外成像技术具有穿透性强、不受光照影响等特点,能克服光照变化对检测任务的影响。但红外图像仍然存在一定的缺点:纹理少、对比度弱。传统的红外航拍目标检测主要基于手工设计特征。刘若阳等[16]提出了一种基于局部协方差矩阵判别模型来克服红外小目标检测中的结构化边缘、非结构化杂波和噪声等问题。袁明等[17]通过中值滤波去噪,然后使用形态学特征抑制背景,最后构造局部对比度通过阈值分割目标。一些学者将红外图像与可见光图像进行融合。Li等[10]提出了光照感知模块,依据光照条件进行可见光与红外图像融合,实现多光谱行人检测。Chen等[18]在SSD架构末端增加解码器模块产生多尺度特征,并引入注意力模块实现红外行人检测器检测性能的提高。
可见光与红外图像融合往往需要同步成像,成本较高。针对仅使用红外图像的航拍目标检测,代牮等[19]通过增加注意力、改进损失函数与预选框筛选改进YOLOv5,实现复杂背景的红外弱小目标检测。本文仅采用红外图像进行目标检测,通过挖掘显著性信息提升算法精度。
1.3 基于视觉显著性的目标检测
显著性目标检测在图像中进行像素级分割[14, 20],是计算机视觉领域的研究热点之一。显著性可理解为一种注意力机制,将显著性图像与热红外图像进行融合能够突出场景中显著性目标[14]。赵鹏鹏等[21]利用融合局部熵对红外弱小目标进行粗定位,再利用改进的视觉显著性检测方法获得感兴趣区域的显著图,最后利用阈值分割提取红外弱小目标。赵兴科等[14]采用BASNet生成热红外图像的显著图进行图像增强,并基于轻量化网络YOLOv3-MobileNetv2实现机载红外目标检测。本文使用深度显著性目标检测网络U2-Net[15]生成热红外图像的显著性图,并在第3章对结果进行评估。
2. 本文算法
针对红外航拍图像存在的检测目标小、图像纹理少、对比度弱的问题,本文主要研究融合视觉显著性的红外航拍行人检测。本章首先分析YOLOv4基准模型,然后分析针对红外航拍场景的锚框重聚类,最后重点介绍生成热红外图像显著图网络U2-Net以及两种显著图融合方式。
2.1 YOLOv4目标检测算法
YOLOv4基于YOLOv3,分别在网络的输入端、主干网络、颈部网络、输出端引入先进方法进行改进,在检测精度上显著提升,实现速度和精度的平衡。
1)输入端:采用Mosaic、CutMix等数据增强方式进行预处理,提高训练速度和检测精度。采用自抗扰训练和CmBN(Cross-Iteration mini-Batch Normalizartion)提升网络泛化性。
2)主干网络:提出基于密集连接结构和CSP(Cross Stage Partial)的新主干CSPDarknet53来提取特征。
3)颈部网络:用于多尺度特征提取。采用SPP(Spatial Pyramid Pooling)和PANet(Path Aggregation Network)结合的方式替代之前的特征金字塔(Feature Pyramid Network, FPN))作为特征融合网络。能够在仅增加少量推理时间的同时显著提升检测精度。
4)输出端:又称检测头,输出最终检测结果。YOLO的输出主要分为3部分:边界框位置信息、边界框置信度、目标分类信息。YOLOv4采用CIOU(Complete-IOU))损失函数,并在预选框筛选阶段采用DIOU_NMS代替原始NMS,提升检测精度。
YOLOv4-tiny是通过减少YOLOv4主干和颈部中CSP结构、去掉SPP结构、减少输出头优化设计的轻量级网络。针对单类别行人检测,本文采用的YOLOv4-tiny结构如图 1所示。
2.2 基于K-Means的锚框重聚类
自YOLOv2开始,YOLO将锚框作为先验知识加入到边界框回归中,YOLOv4边界框回归公式如下:
$$ \begin{array}{l} {b_x} = \sigma ({t_x}) + {c_x} \hfill \\ {b_y} = \sigma ({t_y}) + {c_y} \hfill \\ {b_w} = {p_w}{{\text{e}}^{{t_w}}} \hfill \\ {b_h} = {p_h}{{\text{e}}^{{t_h}}} \hfill \\ \end{array} $$ (1) 式中:bx、by是边界框的中心点位置坐标;bw、bh是边界框的宽、高。如图 1所示,YOLO通过网络训练获得边界框参数。其中tx,ty是边界框相对特征图网络单元格左上角坐标的偏移量;cx、cy是特征图网络单元格左上角坐标;tw、th是相对锚框的缩放比例;pw、ph是从数据集中聚类的锚框。
高质量的锚框设计可提升检测效果[20]。YOLOv4-tiny中原始锚框尺寸适用于尺度变化较大的场景,针对航拍场景,需要对锚框大小重新设计。锚框聚类采用K-Means算法,并采用交并比(Intersection of Union, IOU)度量[8],公式为:
$$ d(\text { box }, \text { anchor })=1-\operatorname{IOU}(\text { box, anchor })$$ (2) 2.3 U2-Net生成显著图
无人机航拍行人目标与地面视角的行人目标存在一定差异,由于拍摄角度不同,航拍图像中的行人目标边界几何特性相对较弱。U2-Net[15]是针对显著性目标检测设计的先进网络,能够捕捉不同尺度上下文信息,可有效提取图像中的显著性目标。
U2-Net[15]是基于encoder-decoder结构设计两层嵌套U形网络,整体结构如图 2所示。底层设计了RSU(residual U-block)结构,顶层设计了“U”形网络,整体由不同层数的RSU模块所组成,这种嵌套U结构在提取多尺度特征上表现良好,同时在聚合阶段的多层次特征上也有较好的表现,且不需要预训练网络进行迁移学习,灵活性强。另外,加深模型U2-Net可获得更高的分辨率,且不会显著增加内存和计算成本。
U2-Net中使用了一种新的残差子块RSU模块(residual U-block),结构如图 3所示。RSU模块中,L表示编码器中的层数,M表示RSU中间层的通道数,输入通道数与输出通道数分别用Cin与Cout表示。编码器中的层数越大,对大尺度信息的处理能力越强。RSU结构也是一个小型的U型结构,能实现不同尺度感受野特征信息的融合,提升网络性能。
利用U2-Net生成显著图实例如图 4所示,在多种复杂场景下,显著图均能提取出行人目标,因此,可利用显著图融合热红外图像进行图像增强。
2.4 显著图融合增强热红外图像
红外航拍数据集ComNet[22]将单通道的热红外图像转换为RGB格式的三通道伪彩色图像,转换方式依据冷暖色调平滑渐变。通过U2-Net获得显著图后,采用两类图像融合方案。
方案一通道替换:如图 5所示,对三通道伪彩色图像进行通道替换,依次使用显著图替换3个通道生成新的融合图像。
方案二加权融合:将显著图与转化后的伪彩色图像进行加权融合,得到增强图像,如图 6所示。加权融合不仅保留了图像中的纹理信息,且使得图像中的行人目标区域更加显著。
3. 实验
3.1 数据集与评价指标
实验使用ComNet数据集[22],该数据集由大疆无人机DJIM600 PRO搭载FLIR热红外相机Vue Pro采集不同时期不同场景下的行人热红外图像数据,无人机飞行的高度为20~40 m,图像分辨率为640×512。部分实例如图 7所示。
该数据集包含多个场景,例如运动场、校园、中午行人密集的食堂入口以及夜间行人稀少的走廊。为了保证模型的有效性,训练集和测试集使用了不同场景下采集的热图像。从数据集中提取仅包含行人目标的热红外图像,训练集包括819张图像,其中包括3130个行人实例,测试集包括80张图像,其中包括407个行人实例[22]。
为对行人目标的检测结果进行评估,本文使用评价指标包括:精确率(Precision)、召回率(Recall)和平均精度(Average Precision, AP)评价指标。AP50表示设置IOU阈值为0.5时,类别的AP值[14]。
3.2 实验环境
实验平台操作系统为Windows10,CPU为Intel i7-8750H(2.2 GHz),GPU为NVIDIA GTX1060GPU、16G内存。采用PyTorch深度学习框架,开发环境为Python 3.8.0,CUDA11.1。
设置训练次数为100 epoch,设置输入网络的图片大小为416×416,学习率为0.001,batch_size为8。
3.3 实验结果与分析
3.3.1 K-Means锚框重聚类
为提高检测精度,利用K-Means算法对数据集的锚框重新聚类,得到6组锚框数据,如表 1所示。重聚类的anchor与数据集的平均IOU较原始anchor提高了32.76%。基于融合显著图和YOLOv4-tiny,经过anchor聚类后的模型精度增加了0.3%,说明精确的锚框设计,能有效提高检测精度。
表 1 K-Means锚框聚类结果Table 1. The results of anchor box re-clusteredModels Anchor Box IOU/% YOLOv4-tiny (10, 14) (23, 27) (37, 58)
(81, 82) (135, 169) (344, 319)49.32% Ours (14, 39) (21, 69) (26, 95)
(38, 85) (33, 113) (45, 130)82.08% 3.3.2 U2-Net显著图融合分析
文献[14]中证明了BASNet作为显著图提取网络的有效性。类似地,U2-Net对热红外图像进行处理,提取出行人目标,并将其处理为二值掩膜图像的形式输出。为评估U2-Net显著图提取的有效性,为后续图像融合方式研究提供有力支撑,选择典型YOLOv3和YOLOv4-tiny算法为基础,将U2-Net和BASNet生成的显著图进行不同数据融合方式对比。
如表 2所示,对比BASNet和U2-Net提取的显著图在不同数据融合方式上效果,无论基于YOLOv3还是YOLOv4-tiny,U2-Net提取的显著图效果明显优于BASNet,能挖掘更多上下文信息。
Data fusion method Salient map extraction method AP50/% YOLOv3 YOLOv4-tiny Original infrared image - 88.8 88.6 Salient map - 77.1 75.6 R channel replaced BASNet 92.7 91.7 U2-Net 94.7 93.7 G channel replaced BASNet 93.8 91.1 U2-Net 94.2 94.7 B channel replaced BASNet 90.5 91.5 U2-Net 92.4 92.9 Weighted fusion BASNet 94.4 92.0 U2-Net 95.3 94.8 如表 2所示,YOLOv4-tiny在原始热红外数据集的AP值为88.6%,在显著图数据上AP值为75.6%,表明显著图图像具有一定的有效信息,但U2-Net提取的显著图仅为二值掩膜图像,原始红外图像比显著图图像具有更多的纹理信息。通道替换的数据融合方式都可提高行人检测精度,替换R、G、B通道分别比基准模型AP值增加了5.1%,6.1%和4.3%。显然面向低对比度的红外图像,替换显著图通道的方式能够增加图像对比度,提升检测效果。同样,加权融合的方式AP值增加了6.2%,即加权融合方式效果优于通道替换,说明加权融合可使用更多的信息。表明了融合热红外图像与显著图的数据增强方法对行人目标检测的有效性,通过加权融合方式进行数据融合比通道替换数据融合表现更好。
图 8是基于YOLOv4-tiny采用不同融合方式的推理实例。显然,使用热红外图像与显著图融合后的图像能够明显增强目标显著性。针对多个场景的行人目标检测,增强后的图像比单独使用热红外图像效果更好,原热红外图像中存在明显漏检,融合显著图进行增强后,行人漏检情况明显改善。同时,不同的通道替换方式与融合方式对行人目标检测结果的影响也不相同,通过替换G通道进行图像融合在目标置信度上优于其他通道替换融合方式。图 8中,通过加权融合方式检测行人目标比通道替换检测目标框更准确,置信度更高,例如在目标较多的场景(图 8(c))中,加权融合方式可检测出右下角的两个行人目标,明显改善漏检情况。
3.3.3 与先进目标检测器的对比
为进一步验证本文图像显著图加权融合方式的有效性,将本文融合算法与IRA-YOLOv3[23]、赵兴科等[14]提出的方法、YOLOv3等几种先进红外目标检测算法在ComNet数据集[22]的表现以及模型体积进行对比,实验结果如表 3所示。
表 3 与先进目标检测器的对比Table 3. Comparison of advanced object detectors由表 3可见,本文方法在精度上相比于IRA-YOLOv3[23]和赵兴科等[14]提出的方法分别高10.9%、6.0%。在模型体积的对比上,本文方法相比于IRA-YOLOv3多12.4MB,但精度上明显占优。且对YOLOv3、YOLOv3-tiny和YOLOv4-tiny等典型算法,通过显著图加权融合方式进行数据增强相比于原始算法在精度上分别提升了6.5%、7.6%和6.2%,表明本文所设计融合方法的有效性。说明加权融合进行热红外图像数据增强的方式在面向红外航拍场景数据是有效的,对其他场景具有一定的参考意义。
YOLOv4-tiny相比之前的YOLOv3、YOLOv3-tiny算法在运行速度上占优[1]。相比YOLOv4-tiny算法在热红外图像的表现,在显著图加权融合后的AP值增加了8.8%。可获得更有利于边缘设备部署的检测模型。
4. 结束语
综上所述,为了解决红外航拍图像存在目标尺寸小、纹理信息少、图像对比度弱的问题,本文提出了一种融合视觉显著性的红外航拍场景行人检测方法。该算法以YOLOv4-tiny作为基础,通过重聚类锚框的方式使得检测器获得更好的效果,并利用U2-Net网络提取热红外图像显著图,通过像素级加权融合方式对热红外图像进行数据增强。基于公开航拍数据集,实验验证了本文方法能够有效提升多种典型检测算法的精度。
-
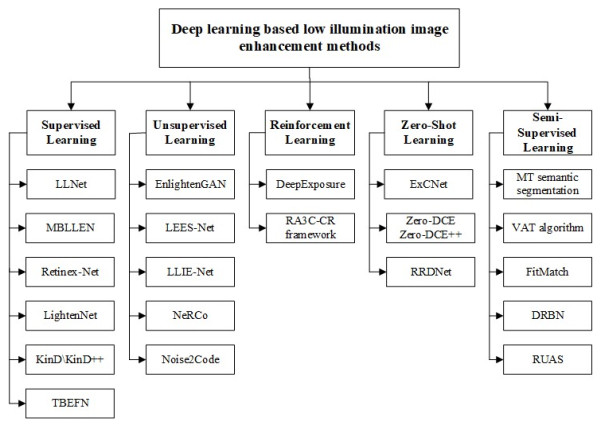
![]()
图 1 传统低照度图像增强代表方法总结
Figure 1. Summary of traditional low-light image enhancement representation methods
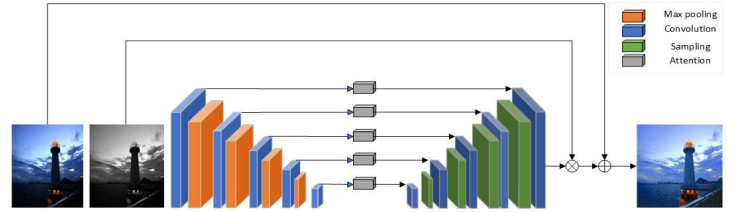
![]()
图 2 基于深度学习的低照度图像增强代表方法
Figure 2. Summary of typical methods for low-light image enhancement based on deep learning
表 1 传统低照度图像增强算法对比
Table 1 Comparison of conventional low-light image enhancement algorithms
Algorithms Key technology Advantage Disadvantage Histogram Equalization[2-6] Changing the histogram distribution of image grey scale intervals Enhanced brightness distribution and sharpness of images Grey scale merge, detail information lost Tone Mapping Algorithm[7-9] Convert high dynamic range images to low dynamic range images Improved image brightness and colour performance Limitations in image display quality Fusion-based Algorithm[10-12] Fusion of multiple image processing results Improved brightness and clarity has advantages Generates fusion artefacts and introduces image distortion Defogging-based Algorithm[13-16] Improve low-light image quality by removing haze effect from images Restore image detail and improve visual quality Partial loss of information, introduction of artefacts, noise Retinex Theory[17-20] Decomposition of the image into reflective and illuminated parts Improved colour balance and detail in images Complex calculations, more light-dependent  下载: 导出CSV
下载: 导出CSV
表 2 基于深度学习的低照度图像增强方法总结
Table 2 Summary of deep learning based low illumination image enhancement methods
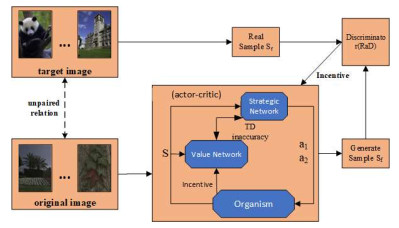
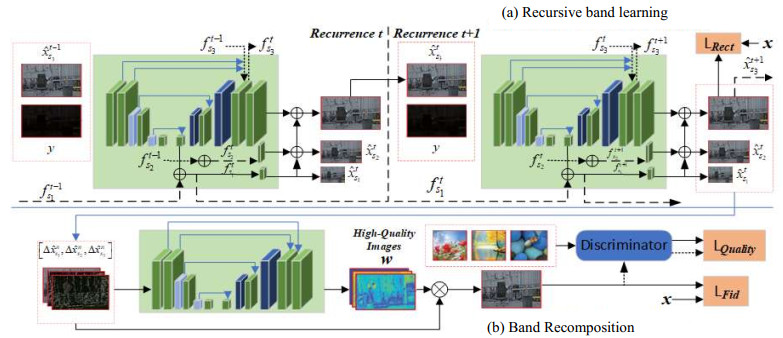
Year Methodology Improvement Advantage Disadvantage 2019 EnlightenGAN[26] Attention-guided U-Net, an image-enhanced GAN network Processes and generates highly realistic multi-type images Introduces artefacts, amplifies noise; not stable enough ExcNet[31] Excludes backlighting and automatically adjusts brightness and contrast Automatically restores detail to backlit images; no need for extensive annotation data Subject to scene limitations, complex scenes may be affected; long training time 2020 Zero-DCE[32] Introduction of contrast loss function and feature network DCE-Net No need for a reference image; enhance the image while retaining detailed information Requires high input image quality; high training costs RRDNet[34] Retinex decomposes residual and salient images Zero sample learning; image details and color saturation are well preserved Relies on accurate reflection and light decomposition; requires high image quality DRBN[37] Recursive banding ensures detail recovery; band reconstruction enhances image Good reconstruction of detail enhancement results using paired and unpaired data training Simple experimental setup, not conducted on wider dataset 2021 Zero-DCE++[33] Accelerated and lightweight version of Zero-DCE Fast inference speed while maintaining performance Enhanced images appear over-enhanced or distorted TBEFN[25] Two-branch structure; adaptive residual block and attention module Handles exposure fusion and image enhancement simultaneously Requires large amount of labelled data; not effective in extreme lighting conditions RUAS[38] Constructing lightweight image enhancement based on Retinex theory Fast and requires few computational resources; very effective Performance and computational efficiency need further improvement 2022 LEDNet[39] Combined low light enhancement and dark de-blurring Handles both low light and blur; new dataset LOL-Blur The dataset does not contain other low-light environments and shooting scenes LEES-Net[27] Attention to mechanisms for positioning and dynamic adjustment Good generalization ability, robustness and visual effects Long training time and lack of real-time capability; artifacts and oversmoothing issues D2HNet[40] Joint denoising and deblurring using hierarchical networks High-quality image restoration for short and long duration shots Training data quality needs to be improved 2023 Literature[41] Introduction of a new framework for appearance and structural modelling Structural features guide appearance enhancements, producing lifelike results Simple model structure; no real-time enhancement Noise2Code[42] Projection based image denoising network algorithm Implementing joint training of denoising networks and VQGAN models Applications have some limitations; adaptability to complex degradation models NeRCo[28] Control of adaptable fitting functions to unify scene degradation factors Semantic Oriented Supervision for Improving Perceptual Friendliness and Robustness A priori limitations in text images; validity not verified in a wider range of scenarios DecNet[43] Decomposition and Tuning Networks and Self-Supervised Fine-Tuning Strategies Efficient and lightweight network with no manual tuning for good performance Degradation problems in images taken in real low-light conditions 2024 Multi-Channel Retinex[44] Multi-Channel Retinex Image Enhancement Network, Design Initialization Module Split channel enhancement is used to solve the problem of color deviation Higher model complexity, requires paired data training Retinexmamba[45] Integration of Retinexformer learning framework and introduction of light fusion state space models Improve the processing speed by using state space model and maintain the image quality during enhancement Lack of some non-reference image quality evaluation metrics LYT-NET[46] YUV separates luminance and chrominance and introduces a blending loss function Simplified light-color information separation reduces model complexity Model generalization ability to be verified, limited comparison methods
下载: 导出CSV
表 3 主流低照度图像增强数据集总结
Table 3 Comparison of conventional low-light image enhancement algorithms
Dataset No. of images Image formats Paired/unpaired Real/Synthetic SICE[47] 4413 RGB Paired Real LOL[48] 500 RGB Paired Real VE-LOL[49] 2500 RGB Paired Real+ Synthetic MIT-Adobe FiveK[50] 5000 RAW Paired Real SID[51] 5094 RAW Paired Real SMOID[52] 179 RAW Paired Real LIME[53] 10 RGB unpaired Real ExDARK[54] 7363 RGB unpaired Real
下载: 导出CSV
表 4 基于深度学习的低照度图像增强方法性能对比
Table 4 Performance comparison of deep learning based low illumination image enhancement methods
Year Methodology Network framework Dataset Image formats Evaluation metrics Operational framework PSNR/dB 2019 EnlightenGAN[26] U-Net NPE/MEF/LIME/DICM etc. RGB NIQE PyTorch 17.48 ExcNet[31] CNN IEpsD RGB CDIQA/LOD PyTorch 17.25 2020 Zero-DCE[32] U-Net type network SICE RGB PSNR/SSIM/MAE PyTorch 14.86 RRDNet[34] Retinex Breakdown NPE/MEF/LIME/DICM etc. RGB NIQE/CPCQI PyTorch 14.38 DRBN[37] Recursive network LOL RGB PSNR/SSIM PyTorch 20.13 2021 Zero-DCE++[33] U-Net type network SICE RGB PSNR/SSIM/MAE etc. PyTorch 16.42 TBEFN[25] U-Net type network LOL RGB PSNR/SSIM/NIQE TensorFlow 17.14 RUAS[38] Retinex Breakdown LOL/MIT-AdobeFiveK RGB PSNR/SSIM/LPIPS PyTorch 20.6 2022 LEDNet[39] Neural network LOL-Blur RGB PSNR/SSIM/LPIPS PyTorch 23.86 LEES-Net[27] CNN LOL-v2/LSRW Dark Face RGB PSNR/SSIM/LPIPS/LOE PyTorch 20.2 D2HNet[40] Pyramid network D2(synthetic dataset) RGB PSNR/SSIM/PR PyTorch 26.67 2023 Literature [41] End-to-end network LOL/SID RGB PSNR/SSIM PyTorch 24.62 Noise2Code[42] GAN model SIDD/DND RGB PSNR/SSIM PyTorch — NeRCo[28] Implicit network LOL/LIME/LSRW RGB PSNR/SSIM/NIQE/LOE PyTorch 19.84 DecNet[43] Retinex Breakdown LOL/NPE/MIT-AdobeFiveK RGB PSNR/SSIM/NIQE/LOE PyTorch 22.82 2024 Multi-Channel Retinex[44] Retinex Breakdown LOL/MIT-AdobeFiveK RGB PSNR/SSIM FSIM PyTorch 21.94 Retinexmamba[45] Retinex+Mamba LOL-v1 LOLv2-real RGB PSNR/SSIM/RMSE PyTorch 22.453 LYT-NET[46] YUV Transformer LOLv1/LOLv2-real/LOL-v2-syn YUV PSNR/SSIM Tensorflow 22.38
下载: 导出CSV
-
[1] LIU J, XU D, YANG W, et al. Benchmarking low-light image enhancement and beyond[J]. International Journal of Computer Vision, 2021, 129: 1153-1184. DOI: 10.1007/s11263-020-01418-8
[2] 郭永坤, 朱彦陈, 刘莉萍, 等. 空频域图像增强方法研究综述[J]. 计算机工程与应用, 2022, 58(11): 23-32. GUO Y K, ZHU Y C, LIU L P, et al. A review of research on image enhancement methods in the air-frequency domain[J]. Computer Engineering and Application, 2022, 58(11): 23-32.
[3] Jebadass J R, Balasubramaniam P. Low contrast enhancement technique for color images using intervalvalued intuitionistic fuzzy sets with contrast limited adaptive histogram equalization[J]. Soft Computing, 2022, 26(10): 4949-4960. DOI: 10.1007/s00500-021-06539-x
[4] 杨嘉能, 李华, 田宸玮, 等. 基于自适应校正的动态直方图均衡算法[J]. 计算机工程与设计, 2021, 42(5): 1264-1270. YANG J N, LI H, TIAN C W, et al. Dynamic histogram equalization algorithm based on adaptive correction[J]. Computer Engineering and Design, 2021, 42(5): 1264-1270.
[5] KUO C F J, WU H C. Gaussian probability bi‐histogram equalization for enhancement of the pathological features in medical images[J]. International Journal of Imaging Systems and Technology, 2019, 29(2): 132-145. DOI: 10.1002/ima.22307
[6] LI C, LIU J, ZHU J, et al. Mine image enhancement using adaptive bilateral gamma adjustment and double plateaus histogram equalization[J]. Multimedia Tools and Applications, 2022, 81(9): 12643-12660. DOI: 10.1007/s11042-022-12407-z
[7] Nguyen N H, Vo T V, Lee C. Human visual system model-based optimized tone mapping of high dynamic range images[J]. IEEE Access, 2021, 9: 127343-127355. DOI: 10.1109/ACCESS.2021.3112046
[8] 陈迎春. 基于色调映射的快速低照度图像增强[J]. 计算机工程与应用, 2020, 56(9): 234-239. CHEN Y C. Fast low-light image enhancement based on tone mapping[J]. Computer Engineering and Applications, 2020, 56(9): 234-239.
[9] 赵海法, 朱荣, 杜长青, 等. 全局色调映射和局部对比度处理相结合的图像增强算法[J]. 武汉大学学报, 2020, 66(6): 597-604. ZHAO H F, ZHU R, DU C Q, et al. An image enhancement algorithm combining global tone mapping and local contrast processing[J]. Journal of Wuhan University, 2020, 66(6): 597-604.
[10] 李明悦, 晏涛, 井花花, 等. 多尺度特征融合的低照度光场图像增强算法[J]. 计算机科学与探索, 2022, 17(8): 1904-1916. LI M Y, YAN T, JING H H, et al. Multi-scale feature fusion algorithm for low illumination light field image enhancement[J]. Computer Science and Exploration, 2022, 17(8): 1904-1916.
[11] 张微微. 基于图像融合的低照度水下图像增强[D]. 大连: 大连海洋大学, 2023. ZHANG W W. Low Illumination Underwater Image Enhancement Based on Image Fusion[D]. Dalian: Dalian Ocean University, 2023.
[12] 田子建, 吴佳奇, 张文琪, 等. 基于Transformer和自适应特征融合的矿井低照度图像亮度提升和细节增强方法[J]. 煤炭科学技术, 2024, 52(1): 297-310. TIAN Z J, WU J Q, ZHANG W Q, et al. Brightness enhancement and detail enhancement method for low illumination images of mines based on Transformer and adaptive feature fusion[J]. Coal Science and Technology, 2024, 52(1): 297-310.
[13] DONG X, PANG Y, WEN J, et al. Fast efficient algorithm for enhancement of low lighting video[C]//2011 IEEE International Conference on Multimedia and Expo, 2011: 1-6.
[14] HUO Y S. Polarization-based research on a priori defogging of dark channel[J]. Acta Physica Sinica, 2022, 71(14): 144202. DOI: 10.7498/aps.71.20220332
[15] HONG S, KIM M, LEE H, et al. Nighttime single image dehazing based on the structural patch decomposition[J]. IEEE Access, 2021, 9: 82070-82082. DOI: 10.1109/ACCESS.2021.3086191
[16] SI Y, YANG F, CHONG N. A novel method for single nighttime image haze removal based on gray space[J]. Multimedia Tools and Applications, 2022, 81(30): 43467-43484. DOI: 10.1007/s11042-022-13237-9
[17] LAND E H. The retinex theory of color vision[J]. Scientific American, 1977, 237(6): 108-129. DOI: 10.1038/scientificamerican1277-108
[18] WANG R, ZHANG Q, FU C W, et al. Underexposed photo enhancement using deep illumination estimation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 6849-6857.
[19] CAI Y, BIAN H, LIN J, et al. Retinexformer: one-stage retinex-based transformer for low-light image enhancement[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023: 12504-12513.
[20] REN X, YANG W, CHENG W H, et al. LR3M: robust low-light enhancement via low-rank regularized retinex model[J]. IEEE Transactions on Image Processing, 2020, 29: 5862-5876. DOI: 10.1109/TIP.2020.2984098
[21] Lore K G, Akintayo A, Sarkar S. LLNet: a deep autoencoder approach to natural low-light image enhancement[J]. Pattern Recognition, 2017, 61: 650-662. DOI: 10.1016/j.patcog.2016.06.008
[22] ZHANG Y, ZHANG J, GUO X. Kindling the darkness: a practical low-light image enhancer[C]//Proceedings of the 27th ACM International Conference on Multimedia, 2019: 1632-1640.
[23] ZHANG Y, GUO X, MA J, et al. Beyond brightening low-light images[J]. International Journal of Computer Vision, 2021: 1013-1037.
[24] LI C, GUO J, PORIKLI F, et al. LightenNet: a convolutional neural network for weakly illuminated image enhancement[J]. Pattern Recognition Letters, 2018, 104: 15-22. DOI: 10.1016/j.patrec.2018.01.010
[25] LU K, ZHANG L. TBEFN: a two-branch exposure-fusion network for low-light image enhancement[J]. IEEE Transactions on Multimedia, 2021, 23: 4093-4105. DOI: 10.1109/TMM.2020.3037526
[26] JIANG Y, GONG X, LIU D, et al. EnlightenGAN: deep light enhancement without paired supervision[J]. IEEE Transactions on Image Processing, 2021, 30: 2340-2349. DOI: 10.1109/TIP.2021.3051462
[27] LI X, HE R, WU J, et al. LEES-Net: fast, lightweight unsupervised curve estimation network for low-light image enhancement and exposure suppression[J]. Displays, 2023, 80: 102550. DOI: 10.1016/j.displa.2023.102550
[28] YANG S, DING M, WU Y, et al. Implicit neural representation for cooperative low-light image enhancement[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023: 12918-12927.
[29] YU R, LIU W, ZHANG Y, et al. Deepexposure: learning to expose photos with asynchronously reinforced adversarial learning[J]. Advances in Neural Information Processing Systems, 2018, 31: 7429-7439.
[30] 周腾威. 基于深度学习的图像增强算法研究[D]. 南京: 南京信息工程大学, 2021. ZHOU T W. Research on Image Enhancement Algorithm Based on Deep Learning[D]. Nanjing: Nanjing University of Information Engineering, 2021.
[31] ZHANG L, ZHANG L, LIU X, et al. Zero-shot restoration of back-lit images using deep internal learning[C]//Proceedings of the 27th ACM International Conference on Multimedia, 2019: 1623-1631.
[32] GUO C, LI C, GUO J, et al. Zero-reference deep curve estimation for low-light image enhancement[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 1780-1789.
[33] LI C, GUO C, CHEN C L. Learning to enhance low-light image via zero-reference deep curve estimation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 44(8): 4225-4238.
[34] ZHU A, ZHANG L, SHEN Y, et al. Zero-shot restoration of underexposed images via robust retinex decomposition[C]//2020 IEEE International Conference on Multimedia and Expo (ICME), 2020, DOI: 10.1109/ICME46284.2020.9102962.
[35] SOHN K, BERTHELOT D, CARLINI N, et al. Fixmatch: simplifying semi-supervised learning with consistency and confidence[J]. Advances in Neural Information Processing Systems, 2020, 33: 596-608.
[36] LIU Y, TIAN Y, CHEN Y, et al. Perturbed and strict mean teachers for semi-supervised semantic segmentation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 4258-4267.
[37] YANG W, WANG S, FANG Y, et al. From fidelity to perceptual quality: a semi-supervised approach for low-light image enhancement [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 3063-3072.
[38] LIU R, MA L, ZHANG J, et al. Retinex-inspired unrolling with cooperative prior architecture search for low-light image enhancement [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021: 10561-10570.
[39] ZHOU S, LI C, CHANGE LOY C. LEDNet: joint low-light enhancement and deblurring in the dark[C]//European Conference on Computer Vision, 2022: 573-589.
[40] ZHAO Y, XU Y, YAN Q, et al. D2hnet: Joint denoising and deblurring with hierarchical network for robust night image restoration [C]//European Conference on Computer Vision, 2022: 91-110.
[41] XU X, WANG R, LU J. Low-Light Image Enhancement via Structure Modeling and Guidance[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023: 9893-9903.
[42] Cheikh Sidiyadiya A. Generative prior for unsupervised image restoration[D]. Ahmed Cheikh Sidiya: West Virginia University, 2023.
[43] LIU X, XIE Q, ZHAO Q, et al. Low-light image enhancement by retinex-based algorithm unrolling and adjustment[J]. IEEE Transactions on Neural Networks and Learning Systems, 2023, 35(11): 2162-2388.
[44] 张箴, 鹿阳, 苏奕铭, 等. 基于多通道Retinex模型的低照度图像增强网络[J]. 信息与控制, 2024, 53(5): 652-661. ZHANG Z, LU Y, SU Y M, et al. Low-light image enhancement network based on multi-channel Retinex model[J]. Information and Control, 2024, 53(5): 652-661.
[45] BAI J, YIN Y, HE Q. Retinexmamba: retinex-based mamba for low-light image enhancement[J]. arXiv preprint arXiv: 2405.03349, 2024.
[46] Brateanu A, Balmez R, Avram A, et al. Lyt-net: lightweight yuv transformer-based network for low-light image enhancement[J]. arXiv preprint arXiv: 2401.15204, 2024.
[47] CAI J, GU S, ZHANG L. Learning a deep single image contrast enhancer from multi-exposure images[J]. IEEE Transactions on Image Processing, 2018, 27(4): 2049-2062.
[48] WEI C, WANG W, YANG W, et al. Deep retinex decomposition for low-light enhancement[J]. arXiv preprint arXiv: 1808.04560, 2018.
[49] LIU J, XU D, YANG W, et al. Benchmarking low-light image enhancement and beyond[J]. International Journal of Computer Vision, 2021, 129: 1153-1184.
[50] Bychkovsky V, Paris S, CHAN E, et al. Learning photographic global tonal adjustment with a database of input/output image pairs[C]//CVPR of IEEE, 2011: 97-104.
[51] CHEN C, CHEN Q, XU J, et al. Learning to see in the dark[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 3291-3300.
[52] JIANG H, ZHENG Y. Learning to see moving objects in the dark[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019: 7324-7333.
[53] GUO X, LI Y, LING H. LIME: Low-light image enhancement via Illumination Map Estimation[J]. IEEE Transactions on Image Processing, 2017, 26(2): 982-993.
[54] LOH Y P, CHAN C S. Getting to know low-light images with the exclusively dark dataset[J]. Computer Vision and Image Understanding, 2019, 178: 30-42.
[55] SARA U, AKTER M, UDDIN M S. Image quality assessment through FSIM, SSIM, MSE and PSNR——a comparative study[J]. Journal of Computer and Communications, 2019, 7(3): 8-18.
[56] Mittal A, Soundararajan R, Bovik A C. Making a "Completely Blind" image quality analyzer[J]. IEEE Signal Processing Letters, 2013, 20(3): 209-212.
[57] ZHANG R, Isola P, Efros A A, et al. The unreasonable effectiveness of deep features as a perceptual metric[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 586-595.
[58] HU S, YAN J, DENG D. Contextual information aided generative adversarial network for low-light image enhancement[J]. Electronics, 2021, 11(1): 32.
[59] YANG S, ZHOU D, CAO J, et al. Rethinking low-light enhancement via transformer-GAN[J]. IEEE Signal Processing Letters, 2022, 29: 1082-1086.
[60] PAN Z, YUAN F, LEI J, et al. MIEGAN: mobile image enhancement via a multi-module cascade neural network[J]. IEEE Transactions on Multimedia, 2022, 24: 519-533.
[61] CHEN X, LI J, HUA Z. Retinex low-light image enhancement network based on attention mechanism[J]. Multimedia Tools and Applications, 2023, 82(3): 4235-4255.
[62] ZHANG Q, ZOU C, SHAO M, et al. A single-stage unsupervised denoising low-illumination enhancement network based on swin-transformer[J]. IEEE Access, 2023, 11: 75696-75706.
[63] YE J, FU C, CAO Z, et al. Tracker meets night: a transformer enhancer for UAV tracking[J]. IEEE Robotics and Automation Letters, 2022, 7(2): 3866-3873.
[64] Kanev A, Nazarov M, Uskov D, et al. Research of different neural network architectures for audio and video denoising[C]//2023 5th International Youth Conference on Radio Electronics, Electrical and Power Engineering (REEPE) of IEEE, 2023, 5: 1-5.
[65] FENG X, LI J, HUA Z. Low-light image enhancement algorithm based on an atmospheric physical model[J]. Multimedia Tools and Applications, 2020, 79(43): 32973-32997.
[66] JIA D, YANG J. A multi-scale image enhancement algorithm based on deep learning and illumination compensation[J]. Traitement du Signal, 2022, 39(1): 179-185.











计量
- 文章访问数: 122
- HTML全文浏览量: 19
- PDF下载量: 56
