
Infrared Images with Super-resolution Based on Deep Convolutional Neural Network
-
摘要: 由于器件及工艺等技术限制,红外图像分辨率相对可见光图像较低,存在细节纹理特征模糊等不足。对此,本文提出一种基于深度卷积神经网络(convolutional neural network,CNN)的红外图像超分辨率重建方法。该方法改进残差模块,降低激活函数对信息流影响的同时加深网络,充分利用低分辨率红外图像的原始信息。结合高效通道注意力机制和通道-空间注意力模块,使重建过程中有选择性地捕获更多特征信息,有利于对红外图像高频细节更准确地进行重建。实验结果表明,本文方法重建红外图像峰值信噪比(peak signal to noise ratio,PSNR)优于传统的Bicubic插值法以及基于CNN的SRResNet、EDSR、RCAN模型。当尺度因子为×2和×4时,重建图像的平均PSNR值比传统Bicubic插值法分别提高了4.57 dB和3.37 dB。Abstract: Owing to technical limitations regarding the device and process, the resolution of infrared images is relatively low compared to that of visible images, and deficiencies occur such as blurred textural features. In this study, we proposed a super-resolution reconstruction method based on a deep convolutional neural network (CNN) for infrared images. The method improves the residual module, reduces the influence of the activation function on the information flow while deepening the network, and makes full use of the original information of low-resolution infrared images. Combined with an efficient channel attention mechanism and channel-space attention module, the reconstruction process selectively captures more feature information and facilitates a more accurate reconstruction of the high-frequency details of infrared images. The experimental results show that the peak signal-to-noise ratio (PSNR) of the infrared images reconstructed using this method outperforms those of the traditional Bicubic interpolation method, as well as the CNN-based SRResNet, EDSR, and RCAN models. When the scale factor is ×2 and ×4, the average PSNR values of the reconstructed images improved by 4.57 and 3.37 dB, respectively, compared with the traditional Bicubic interpolation method.
-
0. 引言
红外成像系统将人眼无法识别的物体红外辐射信号,通过光电转换与处理,使其成为视觉可见的图像信息。由于红外辐射的特殊性和成像机理,使红外成像技术具有抗干扰能力强、穿透力强、作用距离远等特点。这些优点使其广泛地应用于军用和民用的各个领域。尽管红外成像技术发展迅速,但与可见光成像系统相比,红外图像的空间分辨率往往较低,高分辨率红外成像设备成本昂贵。本文利用图像超分辨率(super-resolution,SR)技术[1],通过深度学习从低分辨率(low-resolution,LR)图像整合信息,重构出高分辨率(high-resolution,HR)图像。在现有红外成像系统的基础上获得更高分辨率的图像。
在可见光图像处理领域中,大量的SR方法被提出。传统方法由早期的基于插值的双线性插值法、双三次插值法(Bicubic)等,该类方法操作计算简单高效,但往往存在锯齿边缘和马赛克现象[2]。随后,Freeman等人[3]提出了基于样本学习的方法,Yang等人[4]提出基于稀疏表示的方法,该类浅层学习模型学习能力有限,重构图像高频细节不够丰富。随着深度学习的发展,由于卷积神经网络(convolutional neural network,CNN)强大的数据拟合能力,基于CNN的模型在图像处理领域引起了广泛的关注。Dong等人[5]提出SRCNN,首次利用卷积神经网络,实现了图像SR。但该方法是将LR图像经过插值上采样至目标尺寸后作为网络输入,引入伪影噪声的同时耗费了运行资源。为此,其团队提出了FSRCNN[6],直接输入LR图像在网络最后使用反卷积操作上采样得到目标尺寸图像。同年,Shi等人[7]提出亚像素卷积ESPCN网络,在网络末端通过像素重新排列组合实现上采样。后续网络模型大多基于此类后置上采样方式。随着ResNet[8]的提出,许多基于CNN的SR方法中引入了残差学习策略,如SRResNet[9]、EDSR[10]等。之后,学者们将注意力机制模块引入图像超分辨率重建模型,如RCAN[11]、SAN[12]、HAN[13]等。注意力机制使网络专注于信息更丰富的特征。
在红外图像处理领域中,一般沿用通用图像处理方法。但红外图像的成像原理、灰度动态范围等特性都与可见光图像存在差异,若直接沿用可见光图像SR方法,这些差异会导致缺少足够的高频先验信息,使红外图像处理效果往往达不到预期,因此需要针对特定的应用对算法进行改进。Choi等人[14]提出了热图像增强网络用于红外热图像SR。He等人[15]提出了具有多个感受场的级联深度网络,用于大规模红外图像SR。Zou等人[16]提出基于跳跃连接的卷积神经网络的红外图像SR网络,通过卷积层和反卷积层提取图像特征并重建红外图像。这几种方法与SRCNN类似,均为前置上采样方式,往往会引入伪影噪声,且网络深度较浅,学习到的特征比较单一,难以提取红外图像的深层次信息。此外,红外图像普遍存在对比度低、细节纹理模糊等不足,对LR红外图像中缺失的高频细节信息重建也更为困难。
对此,本文构建了一种基于CNN的高效残差注意力网络(efficient residual attention network,ERAN),充分利用LR红外图像信息,以实现高精度红外图像SR。首先,网络通过改进残差模块,在不增加计算开销的前提下,拓宽激活函数前的特征通道数,从而降低激活函数对信息流的影响,获取更加丰富的特征信息,使得LR红外图像信息被充分利用。并将高效的通道注意力机制(efficient channel attention,ECA)嵌入改进的残差模块(improved residual block,IRB)中,共同组成了高效残差组(efficient residual group,ERG),其中ECA避免了维度缩减的同时可以使网络专注于信息量更大的特征。最后,在上采样模块前加入通道-空间注意力模块(channel-spatial attention,CSA),对通道和位置之间的整体相关性进行建模,保存更多红外图像的高频细节。该网络提升了红外图像SR过程中对图像特征提取和细节恢复的有效性和准确性。
1. 网络结构
1.1 整体结构
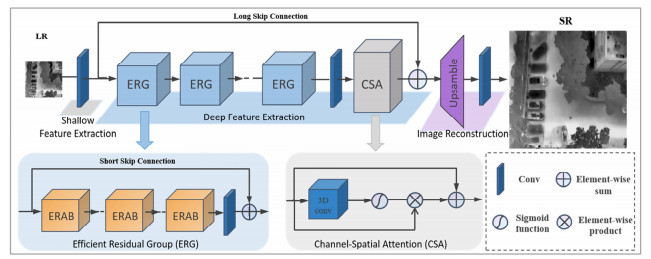
如图 1所示,本文提出的ERAN包括浅层特征提取、深层特征提取和图像重建3部分。具体地,给定的LR图像$ {I_\text{LR}} \in {R^{H \times W \times {C_\text{in}}}} $作为网络的输入,使用一个卷积层从LR输入中提取浅层特征$ {F_0} \in {R^{H \times W \times {C_{}}}} $:
![]() 图 1 基于CNN的高效残差注意力网络结构(ERAN)Figure 1. Efficient residual attention network (ERAN) based on CNN
图 1 基于CNN的高效残差注意力网络结构(ERAN)Figure 1. Efficient residual attention network (ERAN) based on CNN$$ {F_0} = {H_\text{SF}}\left( {{I_\text{LR}}} \right) $$ (1) 式中:Cin、C分别为输入特征和中间特征的通道数,对于红外图像Cin=1。HSF(·)为卷积运算。浅层特征提取可以简单地将输入从低维空间映射到高维空间。该卷积层可以帮助更好地学习视觉表示,并使网络更加稳定。之后,进行深度特征提取HDF(·),进一步得到深度特征FDF:
$$ {F_\text{DF}} = {H_\text{DF}}\left( {{F_0}} \right) $$ (2) 式中:HDF(·)表示经过N个ERG,一个卷积核为3×3的卷积层HCONV(·)和一个CSA后对深度特征进行提取,它可以逐步将中间特征处理为:
$$ \begin{aligned} & F_i=H_{\mathrm{ERG}_i}\left(F_{i-1}\right), i=1, 2, \cdots, N, \\ & F_{\mathrm{DF}}=H_{\mathrm{CSA}}\left(H_{\mathrm{CONV}}\left(F_N\right)\right) \end{aligned}$$ (3) 式中:$ H_{\mathrm{ERG}_i}(\cdot) $表示经过第i个ERG后提取的特征,这一部分的尾部引入了一个卷积层,可更好地聚合深度特征信息;HCSA(·)产生通道-空间注意,以区别地获取特征信息。然后,再加入一个长跳跃连接以融合浅层特征和深层特征,最后通过一个上采样模块,重构高分辨率图像的结果为:
$$ F \uparrow=H \uparrow\left(F_0+F_{\mathrm{DF}}\right) $$ (4) 式中:F↑(·)和F↑分别表示上采样模块和上采样特征。本文采用亚像素卷积(sub-pixel convolutional)作为后置上采样模块,与采用前置上采样方法相比,该方法在计算复杂度和性能方面都更加有效。最后通过一个卷积层将放大后的特征映射生成SR图像:
$$ I_{\mathrm{SR}}=H_{\mathrm{Rec}}\left(F_{\uparrow}\right)=H_{\mathrm{ERAN}}\left(I_{\mathrm{LR}}\right) $$ (5) 式中:HRec(·)和HERAN(·)分别表示重建层和ERAN的功能。
本文采用L1损失函数,目标是使重建生成的图像尽可能接近真实的HR图像,则ERAN的训练目标是令L1损失函数最小化:
$$ L(\Theta)=\frac{1}{N} \sum\limits_{i=1}^N\left\|H_{\mathrm{ERAN}}\left(I_{\mathrm{LR}}^i\right)-I_{\mathrm{HR}}^i\right\|_1 $$ (6) 式中:Θ表示ERAN的参数集。
1.2 高效残差组
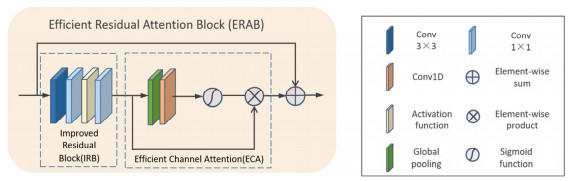
如图 1所示,深度特征提取部分主体结构由N个高效残差组(ERG)堆叠而成,每个ERG包含M个高效残差注意力块(efficient residual attention block,ERAB),一个短跳跃连接和一个卷积层。其中,每个ERAB包含了改进的残差模块(IRB)与高效通道注意力机制(ECA),见图 2,该结构在降低复杂度的同时保持网络性能。
1.2.1 改进的残差模块
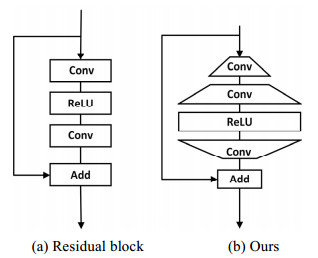
随着ResNet[8]的提出,残差结构被广泛应用于各个任务中。SRResNet[9]首次将残差结构应用于图像SR领域。EDSR[10]网络在其基础上,去除批归一化(batch normalization,BN)层,节约了40%的存储资源并增加了模型的表现力。之后,多数超分辨率重建网络均使用去除BN层的残差块,其结构如图 3(a)所示。
此外,研究表明在SR网络中ReLU激活函数会阻止信息流的传递[17]。传统残差块中卷积层的输入输出维度相等,本文提出的IRB,通过恒等映射,在不增加参数的情况下,减小初始输入维度,扩大激活层的输入通道数,降低了激活函数对信息流的影响,其具体结构如图 3(b)所示。中间残差特征主要经过3个Conv层和一个激活函数层获得,具体可表达为:
$$ {R_{i, j}} = W_{i, j}^3\delta \left( {W_{i, j}^2\left( {W_{i, j}^1{F_{i.j - 1}}} \right)} \right) $$ (7) 式中:Wi, j1、Wi, j2和Wi, j3是ERAB中3个堆叠卷积层的权重集。其中使用3×3的卷积核进行特征提取,再采用1×1的卷积核进行通道数的改变,通过这种方式,在减少了参数量的情况下,使网络更好地对特征信息进行提取。
1.2.2 高效通道注意力机制
RCAN[11]将通道注意力机制应用于图像SR任务中。该机制首先通过在特征层上执行全局池化(global average pooling,GAP),将当前特征压缩成特征向量。然后,通过两个卷积层生成每个特征通道的权值,归一化后加权到每个通道的特征上,自适应地重新缩放每个通道特征,使网络能够专注于更有用的通道信息。
文献[18]证明了GAP后的两个卷积层中的维度衰减对于学习通道之间的依赖关系有不利影响。高效通道注意力机制(ECA)则避免了维度缩减,并有效捕获了跨通道交互。为了有效地计算通道注意,ECA同样通过GAP压缩输入特征映射的空间维度。设输入U=[u1, …, uc, …, uC],其中包含C个大小为H×W的特征图。则通道层面特征$ z \in {R^C} $可通过收缩U的空间维数得到,z的第c个元素可表示为:
$$ {z_c}{\text{ = }}{H_\text{GP}}({u_c}) = \frac{1}{{H \times W}}\sum\limits_{i = 1}^H {\sum\limits_{j = 1}^W {{u_c}\left( {i, j} \right)} } $$ (8) 式中:uc(i, j)表示第c个uc的(i, j)处的特征值;HGP(·)表示全局池化功能。
为了避免维度缩减,ECA采用1D卷积高效实现了局部跨通道交互,提取通道间的依赖关系。最后利用门机制和sigmoid函数从经过GAP聚合的信息中完全捕获通道间的依赖关系:
$$ s = \sigma \left( {{H_{C1{\text{D}}}}\left( z \right)} \right) $$ (9) 式中:σ(·)表示sigmoid函数;HC1D(·)表示1D卷积。最终输出是通过使用激活s重新缩放特征来获得,可表达为:
$$ {\hat u_c} = {H_\text{scale}}\left( {{u_c}, {s_c}} \right) = {s_c} \cdot {u_c} $$ (10) 式中:sc和uc分别为第c个通道中的比例因子和特征。Hscale(·)指它们之间的通道乘法。
1.3 通道-空间注意力机制
在深度特征提取部分的尾部,本文插入了一个CSA模块[13]。该模块使用3D卷积,令3D卷积核与输入特征的多个相邻通道构造的立方体进行卷积,由此同时关注通道和空间特征。具体而言,将3组连续通道分别与一组3×3×3的卷积核,进行3D卷积,可得到3组通道-空间注意力映射Wcsa。注意力映射Wcsa经激活函数后与输入特征执行元素级乘法。最后,将加权结果乘以比例因子β,与输入特征相加以获得加权特征,可表达为:
$$ F_{\mathrm{csa}}=\beta \sigma\left(W_{\mathrm{csa}}\right) F_{\mathrm{IN}}+F_{\mathrm{IN}} $$ (11) 式中:σ(·)是sigmoid函数;Fcsa即是加权后的通道-空间特征。与传统的空间注意和通道注意相比,CSA同时考虑到通道的全局性和空间的局部性,学习通道和位置之间的整体相关性,自适应地对特征进行缩放。
2. 实验
2.1 数据集
本文采用公开的FLIR数据集结合自建数据集来制作红外图像SR任务数据集。FLIR数据集中随机选取7000张8 bit分辨率为640×512的红外图像。该数据集主要用于自动驾驶任务,图像内容主要以白昼和夜晚的街景图为主,包括道路、车辆、行人、建筑等。自建数据集使用非制冷长波红外探测器采集,图像分辨率为640×512,8 bit,主要场景为航拍的建筑、车辆、树木、道路等共3030张。将这些图像作为真实HR红外图像数据集,并在Matlab中采用Bicubic退化模型下采样构建LR红外数据集,下采样尺度因子分别为2和4,构成高-低分辨率图像对。从上述数据集中随机选出30张作为测试数据集,其余用于训练(80%)和验证(20%)。
2.2 评价指标
本文通过主观和客观两种评价方法衡量重建图像质量。主观方法通过人眼观测重建图像予以主观评估。客观方法通过峰值信噪比(peak signal to noise ratio,PSNR)和结构相似性(structure similarity image measure,SSIM)两个常用指标对不同方法重建图像质量进行客观评价。
2.3 实验设置
网络在NVIDIA A100 GPU运行,batch size为16。采用Adam优化器作为训练优化器策略,β1=0.9,β2=0.99,学习率初始化为10-4,然后每2×105次反向传播迭代减少一半。
2.4 实验细节
2.4.1 消融实验
通过实验验证本文所提出网络结构中的ECA、IRB和CSA的有效性。实验制定了5个不同的测试模型,其中基础模型(Base)将ERAB结构替换为传统的残差模块,整个Base模型仅由残差模块和长短跳跃连接组成。M1模型将基础残差模块替换为IRB,M2在M1的基础上加入一个CSA,位于深度特征提取尾部;M3在M1的基础上加入ECA,与IRB共同构成ERAB;最后M4同时应用提出的3个结构。所有模型使用相同的训练集以及网络配置进行训练,尺度因子为2,通过测试集平均PSNR和SSIM值对各个模块进行评估。
2.4.2 对比实验
进一步,为了测试本文提出方法ERAN的有效性,将ERAN与传统的Bicubic插值方法以及其他3种基于CNN的先进SR方法:SRResNet、EDSR、RCAN进行图像重建结果的对比分析。对所有方法使用相同的训练数据,并使用这些方法的作者提供的默认训练设置。分别用×2和×4两种尺度因子,测试30张图像用于重建结果分析。
3. 结果与分析
3.1 消融实验结果
尺度因子为×2时,5种模型的SR的定量分析结果如表 1所示。
表 1 ERAB(包括IRB和ECA)和CSA的研究Table 1. Investigations of ERAB (including IRB and ECA) and CSABase M1 M2 M3 M4 IRB √ √ √ √ CSA √ √ ECA √ √ PSNR/dB 42.44 42.78 42.97 42.86 43.06 SSIM 0.9543 0.9549 0.9552 0.9550 0.9554 由表 1可知,经5种模型重建后所得图像PSNR值分别为42.44 dB、42.78 dB、42.97 dB、42.86 dB、43.06 dB;SSIM值分别为0.9543、0.9549、0.9552、0.9550、0.9554。可以看出,对于无IRB、CSA、ECA模块的Base模型测试结果具有最小的PSNR和SSIM,而随着3种模块的替换和逐步添加,模型的PSNR和SSIM增加,相较于Base模型,M4测试集结果提高了0.62 dB。通过M4与前4种模型对比,分别证明了IRB、CSA、ECA的有效性,并且添加CSA模块的M2相较于添加ECA模块的M3具有更大的PSNR和SSIM,体现出CSA对重建图像超分结果的贡献大于ECA。
3.2 对比实验结果
本文从实验数据测试集中选取4幅不同场景图片,其中TEST_1和TEST_2为×2倍放大尺度因子,TEST_3和TEST_4为×4倍放大尺度因子。在此基础上对比不同方法的超分辨率重建效果,具体如图 4~图 7所示。
![]() 图 4 “TEST_1”使用不同超分辨率重建方法的重建结果(尺度因子为×2)Figure 4. Reconstructed results of "TEST_1" by different super-resolution reconstruction approaches(upscaling factor is ×2)
图 4 “TEST_1”使用不同超分辨率重建方法的重建结果(尺度因子为×2)Figure 4. Reconstructed results of "TEST_1" by different super-resolution reconstruction approaches(upscaling factor is ×2)![]() 图 5 “TEST_2”使用不同超分辨率重建方法的重建结果(尺度因子为×2)Figure 5. Reconstructed results of "TEST_2" by different super-resolution reconstruction approaches(upscaling factor is ×2)
图 5 “TEST_2”使用不同超分辨率重建方法的重建结果(尺度因子为×2)Figure 5. Reconstructed results of "TEST_2" by different super-resolution reconstruction approaches(upscaling factor is ×2)![]() 图 6 “TEST_3”使用不同超分辨率重建方法的重建结果(尺度因子为×4)Figure 6. Reconstructed results of "TEST_3" by different super-resolution reconstruction approaches(upscaling factor is ×4)
图 6 “TEST_3”使用不同超分辨率重建方法的重建结果(尺度因子为×4)Figure 6. Reconstructed results of "TEST_3" by different super-resolution reconstruction approaches(upscaling factor is ×4)![]() 图 7 “TEST_4”使用不同超分辨率重建方法的重建结果(尺度因子为×4)Figure 7. Reconstructed result of "TEST_4" by different super-resolution reconstruction approaches(upscaling factor is ×4)
图 7 “TEST_4”使用不同超分辨率重建方法的重建结果(尺度因子为×4)Figure 7. Reconstructed result of "TEST_4" by different super-resolution reconstruction approaches(upscaling factor is ×4)选取边缘细节信息丰富的局部图像进行放大显示,对比图 4~图 7不同方法及尺度的重建效果。主观上,可以明显看出传统Bicubic方法重建图像结果的边缘模糊,细节纹理信息丢失严重。基于CNN的方法能更好地对图像进行重建,重建图像在目标和背景之间具有更清晰的轮廓,细节丢失较少。本文方法与SRResNet、RDSR和RCAN对比,细节纹理更加突出。由于LR输入中可用的信息有限(尺度因子为×4),高频信息的恢复很困难,但本文提出的ERAN仍然可以通过长、短跳跃连接充分利用有限的LR信息,同时利用空间和通道特征相关性来获得更丰富的特征,从而产生更精细的结果。
客观地,本文通过PSNR和SSIM两个客观指标来评估所有方法的性能。表 2从测试集中选取4张典型图像,前两张为2倍重建结果的PSNR值与SSIM值,后两张为4倍重建结果。表 3中列出了尺度因子为×2和×4的整个测试图像集超分辨率重建的客观指标平均结果。表中体现了本文方法ERAN具有最高的PSNR和SSIM,说明本文建立的网络结构能够在一定程度上有效提升红外图像超分辨率重建的效果。
表 2 典型图像实验结果对比Table 2. Comparison of typical images experiment resultsImages Scale Bicubic
(PSNR/dB)/SSIMSRResNet
(PSNR/dB)/SSIMEDSR
(PSNR/dB)/SSIMRCAN
(PSNR/dB)/SSIMOurs
(PSNR/dB)/SSIMTEST_1 ×2 38.0631/0.9710 43.0650/0.9868 43.1183/0.9869 43.1627/0.9870 43.3488/0.9875 TEST_2 30.8528/0.7505 32.1850/0.7875 32.1907/0.7878 32.1908/0.7880 32.2152/0.7881 TEST_3 ×4 31.8568/0.9091 35.4462/0.9498 35.3748/0.9493 35.7971/0.9516 36.0539/0.9538 TEST_4 28.6532/0.8888 35.3544/0.9551 35.3770/0.9548 35.5273/0.9559 36.1061/0.9586 表 3 测试图像集超分辨率重建结果比较Table 3. Comparison of super-resolution reconstruction results of test image setMethods (PSNR/dB)/SSIM(×2) (PSNR/dB)/SSIM(×4) Bicubic 38.4937/0.9395 32.3882/0.8699 SRResNet 41.6272/0.9220 34.8284/0.8999 EDSR 41.6705/0.9221 35.4601/0.9035 RCAN 42.5441/0.9546 35.5871/0.9042 OURS 43.0616/0.9554 35.7599/0.9053 4. 结论
本文提出了一种基于深度卷积神经网络的红外图像超分辨率重建网络ERAN,该网络使用高效的注意力机制,以及改进残差结构充分利用LR红外图像信息,以实现高精度红外图像SR。将高效的通道注意力机制嵌入改进的残差模块中,使网络获取更加丰富的特征信息并且专注于信息量更大的特征。最后,结合使用通道-空间注意力机制,学习不同通道和位置之间的关系,自适应地重新缩放特征,保存更多的高频细节。在基准数据集上的大量实验结果体现了该模型在准确性和视觉质量方面的有效提升。
-
![]()
图 1 基于CNN的高效残差注意力网络结构(ERAN)
Figure 1. Efficient residual attention network (ERAN) based on CNN
![]()
图 4 “TEST_1”使用不同超分辨率重建方法的重建结果(尺度因子为×2)
Figure 4. Reconstructed results of "TEST_1" by different super-resolution reconstruction approaches(upscaling factor is ×2)
![]()
图 5 “TEST_2”使用不同超分辨率重建方法的重建结果(尺度因子为×2)
Figure 5. Reconstructed results of "TEST_2" by different super-resolution reconstruction approaches(upscaling factor is ×2)
![]()
图 6 “TEST_3”使用不同超分辨率重建方法的重建结果(尺度因子为×4)
Figure 6. Reconstructed results of "TEST_3" by different super-resolution reconstruction approaches(upscaling factor is ×4)
![]()
图 7 “TEST_4”使用不同超分辨率重建方法的重建结果(尺度因子为×4)
Figure 7. Reconstructed result of "TEST_4" by different super-resolution reconstruction approaches(upscaling factor is ×4)
表 1 ERAB(包括IRB和ECA)和CSA的研究
Table 1 Investigations of ERAB (including IRB and ECA) and CSA
Base M1 M2 M3 M4 IRB √ √ √ √ CSA √ √ ECA √ √ PSNR/dB 42.44 42.78 42.97 42.86 43.06 SSIM 0.9543 0.9549 0.9552 0.9550 0.9554  下载: 导出CSV
下载: 导出CSV
表 2 典型图像实验结果对比
Table 2 Comparison of typical images experiment results
Images Scale Bicubic
(PSNR/dB)/SSIMSRResNet
(PSNR/dB)/SSIMEDSR
(PSNR/dB)/SSIMRCAN
(PSNR/dB)/SSIMOurs
(PSNR/dB)/SSIMTEST_1 ×2 38.0631/0.9710 43.0650/0.9868 43.1183/0.9869 43.1627/0.9870 43.3488/0.9875 TEST_2 30.8528/0.7505 32.1850/0.7875 32.1907/0.7878 32.1908/0.7880 32.2152/0.7881 TEST_3 ×4 31.8568/0.9091 35.4462/0.9498 35.3748/0.9493 35.7971/0.9516 36.0539/0.9538 TEST_4 28.6532/0.8888 35.3544/0.9551 35.3770/0.9548 35.5273/0.9559 36.1061/0.9586
下载: 导出CSV
表 3 测试图像集超分辨率重建结果比较
Table 3 Comparison of super-resolution reconstruction results of test image set
Methods (PSNR/dB)/SSIM(×2) (PSNR/dB)/SSIM(×4) Bicubic 38.4937/0.9395 32.3882/0.8699 SRResNet 41.6272/0.9220 34.8284/0.8999 EDSR 41.6705/0.9221 35.4601/0.9035 RCAN 42.5441/0.9546 35.5871/0.9042 OURS 43.0616/0.9554 35.7599/0.9053
下载: 导出CSV
-
[1] Baker S, Kanade T. Limits on super resolution and how to break them[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2002, 24(9): 1167-1183. http://www.onacademic.com/detail/journal_1000035551419310_c5fb.html
[2] Hou H, Andrews H. Cubic splines for image interpolation and digital filtering[J]. IEEE Transactions on acoustics, speech, and signal processing, 1978, 26(6): 508-517. DOI: 10.1109/TASSP.1978.1163154
[3] Freeman W T, Pasztor E C, Carmichael O T. Learning low-level vision[J]. International Journal of Computer Vision, 2000, 40(1): 25-47. DOI: 10.1023/A:1026501619075
[4] YANG J, Wright J, HUANG T S, et al. Image super-resolution via sparse representation[J]. IEEE transactions on image processing, 2010, 19(11): 2861-2873. DOI: 10.1109/TIP.2010.2050625
[5] DONG C, Loy C C, HE K, et al. Image super-resolution using deep convolutional networks[J]. IEEE Trans Pattern Anal Mach Intell, 2016, 38(2): 295-307. DOI: 10.1109/TPAMI.2015.2439281
[6] DONG C, Loy C C, TANG X. Accelerating the super-resolution convolutional neural network[C]//Proceedings of the European conference on computer vision (ECCV), 2016: 391-407.
[7] SHI W, Caballero J, Huszár F, et al. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2016: 1874-1883.
[8] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016: 770-778.
[9] Ledig C, Theis L, Huszár F, et al. Photo-realistic single image super-resolution using a generative adversarial network[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 4681-4690.
[10] Lim B, Son S, Kim H, et al. Enhanced deep residual networks for single image super-resolution[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2017: 136-144.
[11] ZHANG Y, LI K, LI K, et al. Image super-resolution using very deep residual channel attention networks[C]//Proceedings of the European Conference on Computer Vision (ECCV), 2018: 286-301.
[12] DAI T, CAI J, ZHANG Y, et al. Second-order attention network for single image super-resolution[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 11065-11074.
[13] NIU B, WEN W, REN W, et al. Single image super-resolution via a holistic attention network[C]//Proceedings of the European Conference on Computer Vision (ECCV), 2020: 191-207.
[14] Choi Y, Kim N, Hwang S, et al. Thermal image enhancement using convolutional neural network[C]//2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). 2016: 223-230.
[15] HE Z, TANG S, YANG J, et al. Cascaded deep networks with multiple receptive fields for infrared image super-resolution[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2018, 29(8): 2310-2322. http://www.xueshufan.com/publication/2886209123
[16] ZOU Y, ZHANG L, LIU C, et al. Super-resolution reconstruction of infrared images based on a convolutional neural network with skip connections[J]. Optics and Lasers in Engineering, 2021, 146: 106717. DOI: 10.1016/j.optlaseng.2021.106717
[17] YU J, FAN Y, YANG J, et al. Wide activation for efficient and accurate image super-resolution[J/OL]. arXiv preprint arXiv: 1808.08718, 2018.
[18] WANG Q, WU B, ZHU P, et al. ECA-Net: Efficient channel attention for deep convolutional neural networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 11534-11542.
-
期刊类型引用(3)
1. 赵洪山,王惠东,刘婧萱,杨伟新,李忠航,林诗雨,余洋,吕廷彦. 考虑局部纹理特征和全局温度分布的电力设备红外图像超分辨率重建方法. 电力系统保护与控制. 2025(02): 89-99 .  百度学术
百度学术
2. 朱琨,沈良吉,姜文涛,叶超杰,黎中豪,魏巍,刘吉龙. 基于梯度引导的轻量化红外图像超分辨率重建. 应用光学. 2025(03): 695-702 . 百度学术
3. 徐浙君. 基于优化深度学习的低照度图像超分辨率重建方法的研究. 科技通报. 2024(04): 39-43+53 . 百度学术
其他类型引用(5)




计量
- 文章访问数: 247
- HTML全文浏览量: 75
- PDF下载量: 78
- 被引次数: 8
