

Infrared Vehicle Target Detection Based on Convolutional Neural Network without Pre-training
-
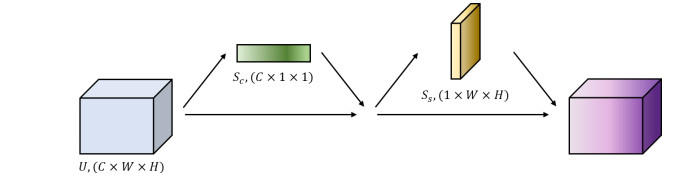
摘要: 为解决基于卷积神经网络的目标检测算法对预训练权重的过度依赖,特别是数据稀缺条件下的红外场景目标检测,提出了融入注意力模块来缓解不进行预训练所带来的检测性能下降的方法。本文基于YOLO v3算法,在网络结构中融入模仿人类注意力机制的SE和CBAM模块,对提取的特征进行通道层面和空间层面的重标定。根据特征的重要程度,自适应地赋予不同权重,最终提升检测精度。在构建的红外车辆目标数据集上,注意力模块能够显著提升无预训练卷积神经网络的检测精度,融入了CBAM模块的网络检测精度为86.3 mAP。实验结果证明了注意力模块能够提升网络的特征提取能力,使网络摆脱对预训练权重的过度依赖。Abstract: To tackle the over-dependence of convolutional neural network-based target detection algorithms on pre-training weights, especially for target detection of infrared scenarios under data-sparse conditions, the incorporation of attention modules is proposed to alleviate the degradation of detection performance owing to the absence of pre-training. This paper is based on the YOLO v3 algorithm, which incorporates SE and CBAM modules in a network that mimics human attentional mechanisms to recalibrate the extracted features at the channel and spatial levels. Different weights are adaptively assigned to the features according to their importance, which ultimately improves the detection accuracy. On the constructed infrared vehicle target dataset, the attention module significantly improved the detection accuracy of the non-pre-trained convolutional neural network. Furthermore, the detection accuracy of the network incorporating the CBAM module was 86.3 mAP, demonstrating that the attention module can improve the feature extraction ability of the network and free the network from over-reliance on the pretrained weights.
-
Key words:
- target detection /
- infrared target /
- deep learning /
- convolutional neural network
-
表 1 改进的DarkNet-53结构
Table 1. The structure of improved DarkNet-53
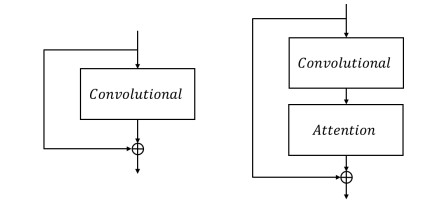
Name Type Num Size Convolutional 32 3×3 Convolutional 64 3×3, 2 Stage 1 $\left( {\begin{array}{*{20}{l}} {\rm{Convolutional}} \\ {\rm{Convolutional}} \\ {\rm{Attention}} \\ \operatorname{Re} {\rm{sidual}} \\ \end{array}} \right) \times 1$ 32
641×1
3×3Convolutional 128 3×3, 2 Stage 2 $\left( {\begin{array}{*{20}{l}} {\rm{Convolutional}} \\ {\rm{Convolutional}} \\ {\rm{Attention}} \\ \operatorname{Re} {\rm{sidual}} \\ \end{array}} \right) \times 2$ 64
1281×1
3×3Convolutional 256 3×3, 2 Stage 3 $\left( {\begin{array}{*{20}{l}} {\rm{Convolutional}} \\ {\rm{Convolutional}} \\ {\rm{Attention}} \\ \operatorname{Re} {\rm{sidual}} \\ \end{array}} \right) \times 8$ 128
2561×1
3×3Convolutional 512 3×3, 2 Stage 4 $\left( {\begin{array}{*{20}{l}} {\rm{Convolutional}} \\ {\rm{Convolutional}} \\ {\rm{Attention}} \\ \operatorname{Re} {\rm{sidual}} \\ \end{array}} \right) \times 8$ 256
5121×1
3×3Convolutional 1024 3×3, 2 Stage 5 $\left( {\begin{array}{*{20}{l}} {\rm{Convolutional}} \\ {\rm{Convolutional}} \\ {\rm{Attention}} \\ \operatorname{Re} {\rm{sidual}} \\ \end{array}} \right) \times 4$ 512
10241×1
3×3 下载: 导出CSV
下载: 导出CSV
表 2 改进的预测分支结构
Table 2. The structure of improved prediction subnet
Name Type Num Size Prediction $\left( {\begin{array}{*{20}{l}} {\rm{Convolutional}} \\ {\rm{Convolutional}} \\ \end{array}} \right) \times 1$ N
2N
N=512, 256, 1281×1
3×3Attention Convolutional (4+1+Ncls) 1×1 YOLO
下载: 导出CSV
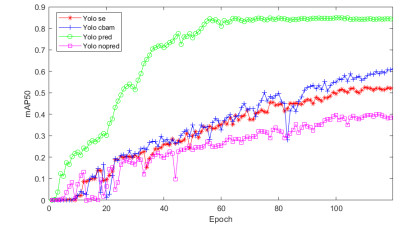
表 3 训练120轮次的实验结果对比
Table 3. The comparison of results when epoch=120
Epoch=120 Precision Recall mAP@0.5 YOLO v3-mscoco-pretrained 82.3 77.0 84.7 YOLO v3-no-pretrained 65.3 22.4 38.9 YOLO v3-SE 68.9 36.2 51.7 YOLO v3-CBAM 78.2 40.5 61.7
下载: 导出CSV
表 4 训练300轮次的实验结果对比
Table 4. The comparison of results when epoch=300
Epoch=300 Precision Recall mAP@0.5 YOLO v3-no-pre-trained 83.7 65.3 80.6 YOLO v3-SE 87.0 72.4 85.6 YOLO v3-CBAM 87.8 75.8 86.3
下载: 导出CSV
-
[1] Otsu N. A threshold selection method from gray-level histograms[J]. IEEE Transactions on Systems, Man, and Cybernetics, 1979, 9(1): 62-66. doi: 10.1109/TSMC.1979.4310076 [2] Dalal N, Triggs B. Histograms of oriented gradients for human detection[C]//Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2005: 886-893. [3] Suykens J A K, Vandewalle J. Least squares support vector machine classifiers[J]. Neural Processing Letters, 1999, 9(3): 293-300. doi: 10.1023/A:1018628609742 [4] REN S, HE K, Girshick R, et al. Faster r-cnn: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 39(6): 1137-1149 doi: 10.1109/TPAMI.2016.2577031 [5] QIN Z, LI Z, ZHANG Z, et al. ThunderNet: Towards real-time generic object detection on mobile devices[C]//Proceedings of the IEEE International Conference on Computer Vision, 2019: 6718-6727. [6] Redmon J, Divvala S, Girshick R, et al. You only look once: unified, real-time object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016: 779-788. [7] DUAN K, BAI S, XIE L, et al. Centernet: keypoint triplets for object detection[C]//Proceedings of the IEEE International Conference on Computer Vision, 2019: 6569-6578. [8] TANG T, ZHOU S, DENG Z, et al. Vehicle detection in aerial images based on region convolutional neural networks and hard negative example mining[J]. Sensors, 2017, 17(2): 336. doi: 10.3390/s17020336 [9] DENG J, DONG W, Socher R, et al. Imagenet: a large-scale hierarchical image database[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2009: 248-255. [10] LIN T Y, Maire M, Belongie S, et al. Microsoft coco: common objects in context[C]//Proceedings of the European Conference on Computer Vision, 2014: 740-755. [11] Redmon J, Farhadi A. YOLOv3: An incremental improvement[DB/OL]. https://arxiv.org/abs/1804.02767.2020-0703. [12] HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 7132-7141. [13] Woo S, Park J, Lee J Y, et al. Cbam: convolutional block attention module[C]//Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany: Springer, 2018: 3-19. [14] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016: 770-778. [15] Krishna K, Murty M N. Genetic K-means algorithm[J]. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 1999, 29(3): 433-439. doi: 10.1109/3477.764879 -





 点击查看大图
点击查看大图

图(9) / 表(4)
计量
- 文章访问数: 280
- HTML全文浏览量: 151
- PDF下载量: 61
- 被引次数: 0
